
4 Device model
4.1 General
Figure 1 depicts the main ObjectTypes of the base device model and their relationship. The drawing is not intended to be complete. For the sake of simplicity only a few components and relations were captured to give a rough idea of the overall structure.
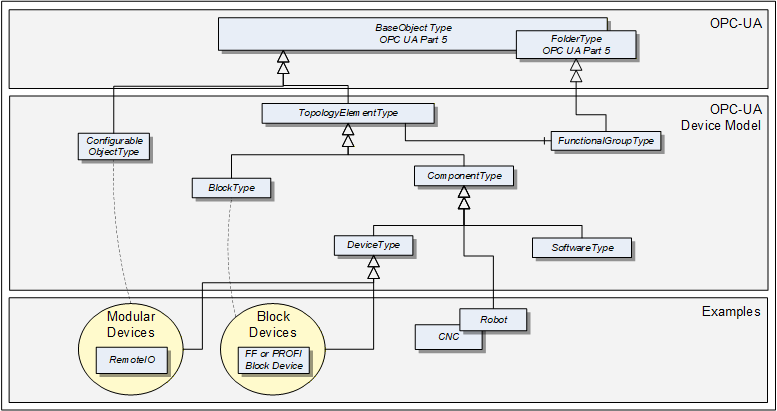
The boxes in this drawing show the ObjectTypes used in this specification as well as some elements from other specifications that help understand some modelling decisions. The upper grey box shows the OPC UA core ObjectTypes from which the TopologyElementType is derived. The grey box in the second level shows the main ObjectTypes that the device model introduces. The components of those ObjectTypes are illustrated only in an abstract way in this overall picture.
The grey box in the third level shows real-world examples as they will be used in products and plants. In general, such subtypes are defined by other organizations.
The TopologyElementType is the base ObjectType for elements in a device topology. Its most essential aspect is the functional grouping concept.
The ComponentType ObjectType provides a generic definition for a Device or parts of a Device where parts include mechanics and/or software. DeviceType is commonly used to represent field Devices.
Modular Devices are introduced to support subdevices and Block Devices to support Blocks. Blocks are typically used by field communication foundations as means to organize the functionality within a Device. Specific types of Blocks will therefore be specified by these foundations.
The ConfigurableObjectType is used as a general means to create modular topology units. If required an instance of this type will be added to the head object of the modular unit. Modular Devices, for example, will use this ObjectType to organize their modules. Block-oriented Devices use it to expose and organize their Blocks.
4.2 Usage guidelines
Annex C describes guidelines for the usage of the device model as base for creating companion specifications as well as guidelines on how to combine different aspects of the same device - defined in different companion specifications - in one OPC UA application.
4.3 TopologyElementType
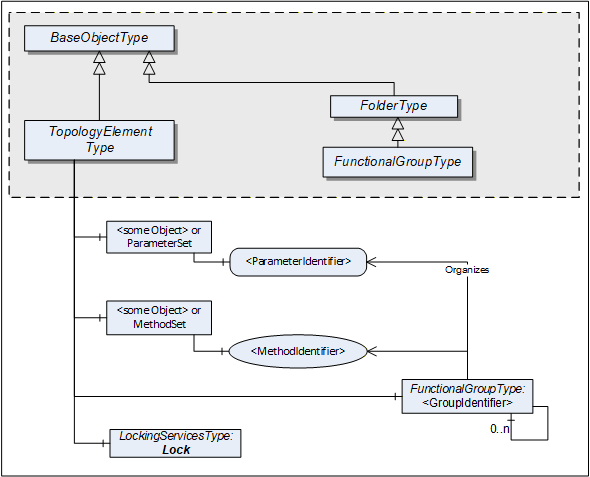
This ObjectType defines a generic model for elements in a device or component topology. Among others, it introduces FunctionalGroups, ParameterSet, and MethodSet. Figure 2 shows the TopologyElementType. It is formally defined in Table 12.
| Attribute | Value | ||||
| BrowseName | 1:TopologyElementType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 0:BaseObjectType defined in OPC 10000-5 | |||||
| 0:HasComponent | Object | 1:<GroupIdentifier> | 1:FunctionalGroupType | OP | |
| 0:HasComponent | Object | 1:Identification | 1:FunctionalGroupType | O | |
| 0:HasComponent | Object | 1:Lock | 1:LockingServicesType | O | |
| 0:HasComponent | Object | 1:ParameterSet | 0:BaseObjectType | O | |
| 0:HasComponent | Object | 1:MethodSet | 0:BaseObjectType | O | |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Information Model |
The TopologyElementType is abstract. There will be no instances of a TopologyElementType itself, but there will be instances of subtypes of this type. In this specification, the term TopologyElement generically refers to an instance of any ObjectType derived from the TopologyElementType.
FunctionalGroups are an essential aspect introduced by the TopologyElementType. FunctionalGroups are used to structure Nodes like Properties, Parameters and Methods according to their application such as configuration, diagnostics, asset management, condition monitoring and others.
FunctionalGroups are specified in 4.4.
A FunctionalGroup called Identification can be used to organize identification information of this TopologyElement (see 4.4.2). Identification information typically includes the Properties defined by the VendorNameplate or TagNameplate Interfaces and additional application specific information.
TopologyElements can also support LockingServices (defined in 7).
Clients shall use the LockingServices if they require to make a set of changes (for example, several Write operations and Method invocations) and where a consistent state is available only after all of these changes have been performed. The main purpose of locking a TopologyElement is avoiding concurrent modifications.
The lock applies to the complete TopologyElement (including all components such as Blocks or modules). Servers can expose a Lock Object on a component TopologyElement to allow independent locking of components, if no lock is applied to the top-level TopologyElement.
If the Online/Offline model is supported (see 6.3), the lock always applies to both the online and the offline version.
ParameterSet and MethodSet are defined as standard containers for systems that have a flat list of Parameters or Methods with unique names. In such cases, the Parameters are components of the "ParameterSet" as a flat list of Parameters. The Methods are kept the same way in the "MethodSet".
The MethodSet is only available if it includes at least one Method.
The components of the TopologyElementType have additional references as defined in Table 13.
| Source Path | References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
| 1:ParameterSet | 0:HasComponent | Variable | 1:<ParameterIdentifier> | 0:BaseDataType | 0:BaseDataVariableType | MP |
4.4 FunctionalGroupType
4.4.1 Model
This subtype of the OPC UA FolderType is used to structure Nodes like Properties, Parameters and Methods according to their application (e.g. maintenance, diagnostics, condition monitoring). Organizes References should be used when the elements are components in other parts of the TopologyElement that the FunctionalGroup belongs to. This includes Properties, Variables, and Methods of the TopologyElement or in Objects that are components of the TopologyElement either directly or via a subcomponent. The same Property, Parameter or Method can be useful in different application scenarios and therefore referenced from more than one FunctionalGroup.
FunctionalGroups can be nested.
FunctionalGroups can directly be instantiated. In this case, the BrowseName of a FunctionalGroup should indicate its purpose. A list of well-known BrowseNames is in 4.4.2.
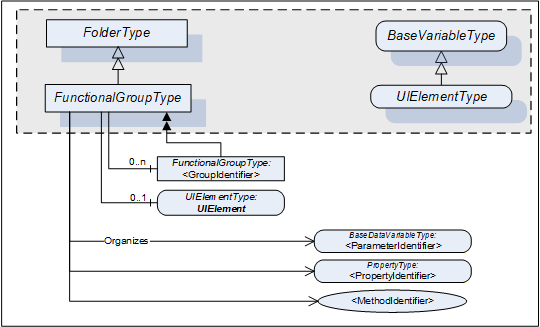
Figure 3 shows the FunctionalGroupType components. It is formally defined in Table 14.
| Attribute | Value | ||||
| BrowseName | 1:FunctionalGroupType | ||||
| IsAbstract | False | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 0:FolderType defined in OPC 10000-5 | |||||
| 0:HasComponent | Object | 1:<GroupIdentifier> | 1:FunctionalGroupType | OP | |
| 0:HasComponent | Variable | 1:UIElement | 0:BaseDataType | 1:UIElementType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Information Model |
All BrowseNames for Nodes referenced by a FunctionalGroup with an Organizes Reference shall be unique.
The Organizes References can be present only at the instance, not the type. Depending on the current state of the TopologyElement the Server can decide to hide or unhide certain FunctionalGroups or (part of) their References. If a FunctionalGroup can be hidden on an instance the TypeDefinition shall use an appropriate ModellingRule like "Optional".
If desirable, Nodes can be also children of FunctionalGroups. If such Nodes are defined, it is recommended to define a subtype of the FunctionalGroupType.
UIElement is the user interface element for this FunctionalGroup. See 4.4.3 for the definition of UIElements.
Examples in Annex B.1 illustrate the use of FunctionalGroups.
4.4.2 Well-Known FunctionalGroup BrowseNames
Table 15 includes a list of FunctionalGroups with name and purpose. If Servers expose a FunctionalGroup that corresponds to the described purpose, they should use the well-known BrowseName with the Namespace of this specification.
| BrowseName | Purpose |
|---|---|
| Configuration | Parameters representing the configuration items of the TopologyElement. If the CurrentWrite bit is set in the AccessLevel Attribute they can be modified by Clients. |
| Tuning | Parameters and Methods to optimize the behavior of the TopologyElement. |
| Maintenance | Parameters and Methods useful for maintenance operations. |
| Diagnostics | Parameters and Methods for diagnostics. |
| Statistics | Parameters and Methods for statistics. |
| Status | Parameters which describe the general health of the TopologyElement. This can include diagnostic Parameters. |
| Operational | Parameters and Methods useful for during normal operation, like process data. |
| OperationCounters | Parameters representing numbers of interest when managing a TopologyElement while it is operated. Examples are the hours of operation, hours in standby, etc. Those are often the base to calculate KPIs (key performance indicators) like the OEE (overall equipment efficiency).
Parameters are often domain specific. Some common ones are defined in the OperationCounter Interface (see 4.5.5). |
| Identification | The Properties of the VendorNameplate Interface, like Manufacturer, SerialNumber or Properties of the TagNameplate will usually be sufficient as identification. If other Parameters or even Methods are required, all elements required shall be organized in a FunctionalGroup called "Identification". See Annex B.1 for an example. |
4.4.3 UIElement Type
Servers can expose UIElements providing user interfaces in the context of their FunctionalGroup container. Clients can load such a user interface and display it on the Client side. The hierarchy of FunctionalGroups represents the tree of user interface elements.
The UIElementType is abstract and is mainly used as filter when browsing a FunctionalGroup. Only subtypes can be used for instances. No concrete UIElements are defined in this specification. FDI (Field Device Integration, see IEC 62769) specifies two concrete subtypes
UIDs (UI Descriptions), descriptive user interface elements, and
UIPs (UI Plug-Ins), programmed user interface elements.
The UIElementType is specified in Table 16.
| Attribute | Value | ||||
| BrowseName | 1:UIElementType | ||||
| IsAbstract | True | ||||
| DataType | 0:BaseDataType | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 0:BaseDataVariableType defined in OPC 10000-5. | |||||
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Information Model |
The Value attribute of the UIElement contains the user interface element. Subtypes have to define the DataType (e.g., XmlElement or ByteString).
4.5 Interfaces
4.5.1 Overview
This clause describes Interfaces with specific functionality that can be applied to multiple types at arbitrary positions in the type hierarchy.
Interfaces are defined in OPC 10000-3.
Figure 4 shows the Interfaces described in this specification.
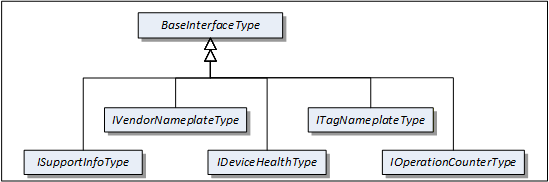
4.5.2 VendorNameplate Interface
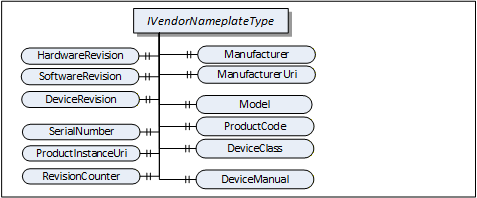
IVendorNameplateType includes Properties that are commonly used to describe a TopologyElement from a manufacturer point of view. They can be used as part of the identification. The Values of these Properties are typically provided by the component vendor.
The VendorNameplate Interface is illustrated in Figure 5 and formally defined in Table 17.
| Attribute | Value | ||||
| BrowseName | 1:IVendorNameplateType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the BaseInterfaceType defined in OPC 10000-5 | |||||
| Product-specific Properties | |||||
|---|---|---|---|---|---|
| 0:HasProperty | Variable | 1:Manufacturer | 0:LocalizedText | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ManufacturerUri | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:Model | 0:LocalizedText | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ProductCode | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:HardwareRevision | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:SoftwareRevision | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:DeviceRevision | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:DeviceManual | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:DeviceClass | 0:String | 0:PropertyType | O |
| Product instance-specific Properties | |||||
|---|---|---|---|---|---|
| 0:HasProperty | Variable | 1:SerialNumber | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ProductInstanceUri | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:RevisionCounter | 0:Int32 | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:SoftwareReleaseDate | 0:DateTime | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:PatchIdentifiers | 0:String[] | 0:PropertyType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Nameplate |
Product type specific Properties:
Manufacturer provides the name of the company that manufactured the item this Interface is applied to. ManufacturerUri provides a unique identifier for this company. This identifier should be a fully qualified domain name; however, it can be a GUID or similar construct that ensures global uniqueness.
Model provides the name of the product.
ProductCode provides a unique combination of numbers and letters used to identify the product. It can be the order information displayed on type shields or in ERP systems.
HardwareRevision provides the revision level of the hardware. SemanticVersionString (a sub-type of String defined in OPC 10000-5) can be used when using the Semantic Versioning format.
SoftwareRevision provides the version or revision level of the software component, the software/firmware of a hardware component, or the software/firmware of the Device. SemanticVersionString (a sub-type of String defined in OPC 10000-5) can be used when using the Semantic Versioning format.
DeviceRevision provides the overall revision level of a hardware component or the Device. As an example, this Property can be used in ERP systems together with the ProductCode Property. SemanticVersionString (a sub-type of String defined in OPC 10000-5) can be used when using the Semantic Versioning format.
DeviceManual allows specifying an address of the user manual. It can be a pathname in the file system or a URL (Web address).
DeviceClass indicates in which domain or for what purpose a certain item for which the Interface is applied is used. Examples are "ProgrammableController", "RemoteIO", and "TemperatureSensor". This standard does not predefine any DeviceClass names. Companion standards that utilize this Interface (device models) will likely introduce such classifications.
Product instance specific Properties:
SerialNumber is a unique production number provided by the manufacturer. This is often stamped on the outside of a physical component and can be used for traceability and warranty purposes.
ProductInstanceUri is a globally unique resource identifier provided by the manufacturer. This is often stamped on the outside of a physical component and can be used for traceability and warranty purposes. The maximum length is 255 characters. If used as QR code, 80 characters is a reasonable size. The recommended syntax of the ProductInstanceUri is: <ManufacturerUri>/<any string> where <any string> is unique among all instances using the same ManufacturerUri.
Examples: "some-company.com/5ff40f78-9210-494f-8206-c2c082f0609c", "some-company.com/snr-16273849" or "some-company.com/model-xyz/snr-16273849".
RevisionCounter is an incremental counter indicating the number of times the configuration data has been modified. An example would be a temperature sensor where the change of the unit would increment the RevisionCounter but a change of the measurement value would not affect the RevisionCounter.
SoftwareReleaseDate defines the date when the software is released. If the version information is about patches, this should be the date of the latest patch. It is additional information for the user.
PatchIdentifiers identify the list of patches that are applied to a software version. The format and semantics of the strings are vendor-specific. The order of the strings shall not be relevant.
Companion specifications can specify additional semantics for the contents of these Properties.
Table 18 specifies the mapping of these Properties to the International Registration Data Identifiers (IRDI) defined in ISO/IEC 11179-6. They should be used if a Server wants to expose a dictionary reference as defined in OPC 10000-19.
| Property | IRDI | Legacy IRDI |
| Manufacturer | 0112/2///61360_7#CBA031 | 0112/2///61987#ABA565#007 |
| ManufacturerUri | 0112/2///61360_7#CBA032 | 0112/2///61987#ABN591#001 |
| Model | 0112/2///61360_7#CBA039 | 0112/2///61987#ABA567#007 |
| SerialNumber | 0112/2///61360_7#CBA050 | 0112/2///61987#ABA951#007 |
| HardwareRevision | 0112/2///61360_7#CBA047 | 0112/2///61987#ABA926#006 |
| SoftwareRevision | 0112/2///61360_7#CBA046 | 0112/2///61987#ABA601#006 |
| DeviceRevision | 0112/2///61987#ABP643#002 | |
| RevisionCounter | 0112/2///61987#ABN603#001 | |
| ProductCode | 0112/2///61360_7#CBA040 | 0112/2///61987#ABA300#006 |
| ProductInstanceUri | 0112/2///61360_7#CBA055 | 0112/2///61987#ABN590#001 |
| DeviceManual | - | - |
| DeviceClass | 0112/2///61360_7#CBA037 | 0112/2///61987#ABA566 - type of product |
| SoftwareReleaseDate | - | |
| PatchIdentifiers | - |
4.5.3 TagNameplate Interface
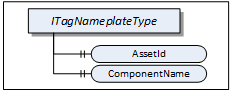
ITagNameplateType includes Properties that are commonly used to describe a TopologyElement from a user point of view.
The TagNameplate Interface is illustrated in Figure 6 and formally defined in Table 19.
| Attribute | Value | ||||
| BrowseName | 1:ITagNameplateType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the BaseInterfaceType defined in OPC 10000-5 | |||||
| 0:HasProperty | Variable | 1:AssetId | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ComponentName | 0:LocalizedText | 0:PropertyType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI TagNameplate |
AssetId is a user writable alphanumeric character sequence uniquely identifying a component. The ID is provided by the integrator or user of the device. It contains typically an identifier in a branch, use case or user specific naming scheme. This could be for example a reference to an electric scheme.
ComponentName is a user writable name provided by the integrator or user of the component.
Table 20 specifies the mapping of these Properties to the International Registration Data Identifiers (IRDI) defined in ISO/IEC 11179-6. They should be used if a Server wants to expose a dictionary reference as defined in OPC 10000-19.
| Property | IRDI |
| AssetId | 0112/2///61987#ABA038 - identification code of device |
| ComponentName | 0112/2///61987#ABA251 - designation of device |
4.5.4 DeviceHealth Interface
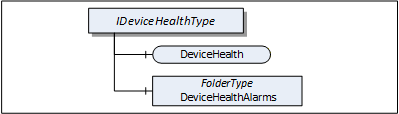
The DeviceHealth Interface includes Properties and Alarms that are commonly used to expose the health status of a Device. It is illustrated in Figure 7 and formally defined in Table 21.
| Attribute | Value | ||||
| BrowseName | 1:IDeviceHealthType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 0:BaseInterfaceType defined in OPC 10000-5 | |||||
| 0:HasComponent | Variable | 1:DeviceHealth | 1:DeviceHealthEnumeration | 0:BaseDataVariableType | O |
| 0:HasComponent | Object | 1:DeviceHealthAlarms | 0:FolderType | O | |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI DeviceHealth |
DeviceHealth indicates the status as defined by NAMUR Recommendation NE107. Clients can read or monitor this Variable to determine the device condition.
The DeviceHealthEnumeration DataType is an enumeration that defines the device condition. Its values are defined in Table 22. Its representation in the AddressSpace is defined in Table 23.
| Name | Value | Description |
|---|---|---|
| NORMAL | 0 | The Device functions normally. |
| FAILURE | 1 | Malfunction of the Device or any of its peripherals. Typically caused device-internal or is process related. |
| CHECK_FUNCTION | 2 | Functional checks are currently performed. Examples: Change of configuration, local operation, and substitute value entered. |
| OFF_SPEC | 3 | "Off-spec" means that the Device is operating outside its specified range (e.g. measuring or temperature range) or that internal diagnoses indicate deviations from measured or set values due to internal problems in the Device or process characteristics. |
| MAINTENANCE_REQUIRED | 4 | Although the output signal is valid, the wear reserve is nearly exhausted or a function will soon be restricted due to operational conditions e.g. build-up of deposits. |
| Attribute | Value | |||||
| BrowseName | 1:DeviceHealthEnumeration | |||||
| IsAbstract | False | |||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other | |
|---|---|---|---|---|---|---|
| Subtype of the 0:Enumeration type defined in OPC 10000-5 | ||||||
| 0:HasProperty | Variable | 0:EnumStrings | 0:LocalizedText [] | 0:PropertyType | ||
| Conformance Units | ||||||
|---|---|---|---|---|---|---|
| DI DeviceHealth |
DeviceHealthAlarms shall be used for instances of the DeviceHealth Alarm Types specified in 4.12 and any other subtypes of DeviceHealthDiagnosticAlarmType.
It is recommended to use the DeviceHealthAlarms folder also for Alarm instances that relate to the health condition of the Device and are not subtypes of DeviceHealthDiagnosticAlarmType
4.5.5 OperationCounter Interface
The IOperationCounterType defines counters for the duration of operation. It is formally defined in Table 24.
| Attribute | Value | ||||
| BrowseName | 1:IOperationCounterType | ||||
| IsAbstract | True | ||||
| Description | Interface defining counters for the duration of operation | ||||
| References | Node Class | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 0:BaseInterfaceType defined in OPC 10000-5 | |||||
| 0:HasProperty | Variable | 1:PowerOnDuration | 0:Duration | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:OperationDuration | 0:Duration | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:OperationCycleCounter | 0:UInteger | 0:PropertyType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI OperationCounter Interface |
PowerOnDuration is the duration the Device has been powered. The main purpose is to determine the time in which degradation of the Device occurred. The details, when the time is counted, is implementation-specific. Companion specifications can define specific rules. Typically, when the Device has supply voltage and the main CPU is running, the time is counted. This can include any kind of sleep mode, but cannot include pure Wake on LAN. This value shall only increase during the lifetime of the Device and shall not be reset when the Device is restarted. The PowerOnDuration is provided as Duration, i.e., in milliseconds or even fractions of a millisecond. However, the Server is not expected to update the value in such a high frequency, but possibly once a minute or once an hour, depending on the application.
OperationDuration is the duration the Device has been powered and performing an activity. This counter is intended for Devices where a distinction is made between switched on and in operation. For example, a drive can be powered on but not operating. It is not intended for Devices always performing an activity like sensors always measuring data. This value shall only increase during the lifetime of the Device and shall not be reset when the Device is restarted. The OperationDuration is provided as Duration, i.e., in milliseconds or even fractions of a millisecond. However, the Server is not expected to update the value in such a high frequency, but possibly once a minute or once an hour, depending on the application.
OperationCycleCounter is counting the times the Device switches from not performing an activity to performing an activity. For example, each time a valve starts moving, is counted. This value shall only increase during the lifetime of the Device and shall not be reset when the Device is restarted.
The child Nodes of the IOperationCounterType have additional Attribute values defined in Table 25.
| BrowsePath | Description Attribute |
| PowerOnDuration | PowerOnDuration is the duration the Device has been powered. The main purpose is to determine the time in which degradation of the Device occurred. The details, when the time is counted, is implementation-specific. Companion specifications can define specific rules. Typically, when the Device has supply voltage and the main CPU is running, the time is counted. This can include any kind of sleep mode, but cannot include pure Wake on LAN. This value shall only increase during the lifetime of the Device and shall not be reset when the Device is restarted. The PowerOnDuration is provided as Duration, i.e., in milliseconds or even fractions of a millisecond. However, the Server is not expected to update the value in such a high frequency, but possibly once a minute or once an hour, depending on the application. |
| OperationDuration | OperationDuration is the duration the Device has been powered and performing an activity. This counter is intended for Devices where a distinction is made between switched on and in operation. For example, a drive can be powered on but not operating. It is not intended for Devices always performing an activity like sensors always measuring data. This value shall only increase during the lifetime of the Device and shall not be reset when the Device is restarted. The OperationDuration is provided as Duration, i.e., in milliseconds or even fractions of a millisecond. However, the Server is not expected to update the value in such a high frequency, but possibly once a minute or once an hour, depending on the application. |
| OperationCycleCounter | OperationCycleCounter is counting the times the Device switches from not performing an activity to performing an activity. For example, each time a valve starts moving, is counted. This value shall only increase during the lifetime of the Device and shall not be reset when the Device is restarted. |
Table 26 - OperationCounter Mapping to IRDIs specifies the mapping of these Properties to the International Registration Data Identifiers (IRDI) defined in ISO/IEC 11179-6. They should be used if a Server wants to expose a dictionary reference as defined in OPC 10000-19.
| Property | IRDI |
| PowerOnDuration | 0112/2///61987#ABP550 |
| OperationDuration | 0112/2///61987#ABN639#001 |
| OperationCycleCounter | 0112/2///61987#ABP545 |
4.5.6 SupportInfo Interface
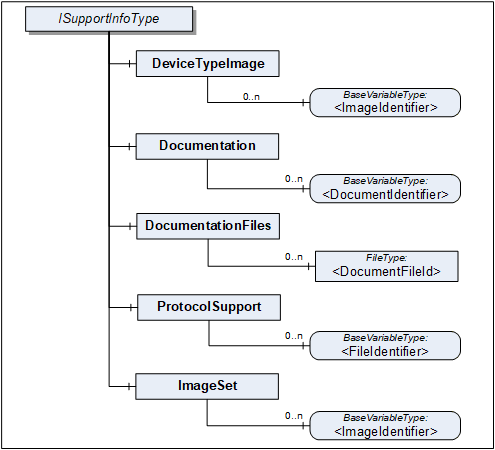
The SupportInfo Interface defines a number of additional data that a commonly exposed for Devices and their components. These include mainly images, documents, or protocol-specific data. The various types of information are organized into different folders. Each information element is represented by a read-only Variable. The information can be retrieved by reading the Variable value.

Figure 8 Illustrates the SupportInfo Interface. It is formally defined in Table 27.
| Attribute | Value | ||||
| BrowseName | 1:ISupportInfoType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the BaseInterfaceType defined in OPC 10000-5 | |||||
| 0:HasComponent | Object | 1:DeviceTypeImage | 0:FolderType | O | |
| 0:HasComponent | Object | 1:Documentation | 0:FolderType | O | |
| 0:HasComponent | Object | 1:DocumentationFiles | 0:FolderType | O | |
| 0:HasComponent | Object | 1:ProtocolSupport | 0:FolderType | O | |
| 0:HasComponent | Object | 1:ImageSet | 0:FolderType | O | |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI DeviceSupportInfo |
Clients should be aware that the contents that these Variables represent can be large. Reading large values with a single Read operation can be impossible due to configured limits in either the Client or the Server stack. The default maximum size for an array of bytes is 1 MiB. It is recommended that Clients use the IndexRange in the OPC UA Read Service (see OPC 10000-4) to read these Variables in chunks, for example, one-megabyte chunks. It is up to the Client whether it starts without an index and repeats with an IndexRange only after an error or whether it always uses an IndexRange.
The components of the ISupportInfoType have additional references as defined in Table 28.
| Source Path | References |
Node
Class | BrowseName |
Data
Type | TypeDefinition | Other |
| 1:DeviceTypeImage | 0:HasComponent | Variable | 1:<ImageIdentifier> | 0:Image | 0:BaseDataVariableType | MP |
| 1:Documentation | 0:HasComponent | Variable | 1:<DocumentIdentifier> | 0:ByteString | 0:BaseDataVariableType | MP |
| 1:DocumentationFiles | 0:HasComponent | Object | 1:<DocumentFileId> | 0:FileType | MP | |
| 1:ProtocolSupport | 0:HasComponent | Variable | 1:<ProtocolSupportIdentifier> | 0:ByteString | 0:BaseDataVariableType | MP |
| 1:ImageSet | 0:HasComponent | Variable | 1:<ImageIdentifier> | 0:Image | 0:BaseDataVariableType | MP |
Pictures can be exposed as Variables organized in the DeviceTypeImage folder. There can be multiple images of different resolutions. Each image is a separate Variable.
All images are transferred as a ByteString. The DataType of the Variable specifies the image format. OPC UA defines BMP, GIF, JPG and PNG (see OPC 10000-3).
Documents in many cases will represent a product manual. They can be exposed as Variables or as FileType instances. Files are useful in particular for large documents.
Documents as Variables are represented as a ByteString and organized in the Documentation folder. The BrowseName of each Node will consist of the filename including the extension that can be used to identify the document type. Typical extensions are ".pdf" or ".txt".
Documents as FileType instances are organized in the DocumentationFiles folder. They are retrieved from the Server by using the FileType Methods. It is recommended to use the MimeType Property to specify the media type of the file based on RFC 2046.
Protocol support files are exposed as Variables organized in the ProtocolSupport folder. They can represent various types of information as defined by a protocol. For example a GSD file.
All protocol support files are transferred as a ByteString. The BrowseName of each Variable shall consist of the complete filename including the extension that can be used to identify the type of information.
Images that are used within UIElements are exposed as separate Variables rather than embedding them in the element. All image Variables will be aggregated by the ImageSet folder. The UIElement shall specify an image by its name that is also the BrowseName of the image Variable. Clients can cache images so they don't have to be transferred more than once.
The DataType of the Variable specifies the image format. OPC UA defines BMP, GIF, JPG and PNG (see OPC 10000-3).
4.5.7 AssetLocationIndication Interface
The asset location indication Interface provides a method for making a device emit visual signals (e.g., blinking LEDs) or audible signals (e.g., sounds) to facilitate its physical identification among other assets.
IAssetLocationIndicationType can be implemented by any object that represents a physical device and that is able to indicate its position by blinking and / or making a sound.
The minimal implementation supports turning a default indication on and off for a specified duration. Optionally a device can declare its supported indication types (audible, visual) and let the client select the used indication types (one or more).
The Interface is formally defined in Table 29.
| Attribute | Value | ||||
| BrowseName | 1:IAssetLocationIndicationType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the BaseInterfaceType defined in OPC 10000-5 | |||||
| 0:HasComponent | Method | 1:StartLocationIndication | M | ||
| 0:HasComponent | Method | 1:StopLocationIndication | M | ||
| 0:HasProperty | Variable | 1:IsIndicating | 0:Boolean | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:UsedIndicationType | 1:LocationIndicationType | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:SupportedIndicationTypes | 1:LocationIndicationType | 0:PropertyType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI AssetLocationIndication |
The read only Property IsIndicating is true when the indication is currently active.
The optional UsedIndicationType can be written to set the indication types that shall be used when StartLocationIndication is called.
4.5.7.1 StartLocationIndication Method
The StartLocationIndication Method is used to start the indication. As a result to this call the IsIndicating property is set to true.
The signature of this Method is specified below. Table 30 and Table 31 specify the Arguments and AddressSpace representation, respectively.
Signature
StartLocationIndication(
[in] 0:Duration IndicationDuration);| Argument | Description |
| IndicationDuration | 0 => infinite duration or duration in milliseconds |
Method Result Codes (defined in Call Service)
| Result Code | Description |
| Bad_InvalidArgument | If the device does not support a duration other than infinite |
| Attribute | Value | ||||
| BrowseName | 1:StartLocationIndication | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| 0:HasProperty | Variable | 0:InputArguments | 0:Argument[] | 0:PropertyType | M |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI AssetLocationIndication |
4.5.7.2 StopLocationIndication Method
The StopLocationIndication Method is used to stop the indication. As a result to this call, the IsIndicating property is set to false. This method also can be called when the indication is already stopped (e.g., because the specified IndicationDuration is over).
The signature of this Method is specified below.
Signature
StopLocationIndication();4.5.8 LocationIndicationType OptionSet
This DataType is used together with the IAssetLocationIndication Interface. It defines flags for the type of location indication. The OptionSet is defined in Table 32. Its representation in the AddressSpace is defined in Table 33.
| Name | Bit No. | Description |
| Visual | 0 | Location indication through optical signals, such as blinking LEDs, if supported by the device. |
| Audible | 1 | Location indication through auditory signals, such as sounds or beeps, if supported by the device. |
| Attribute | Value | |||||
| BrowseName | 1:LocationIndicationType | |||||
| IsAbstract | False | |||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other | |
|---|---|---|---|---|---|---|
| Subtype of the 0:UInt16 DataType defined in OPC 10000-5 | ||||||
| 0:HasProperty | Variable | 0:OptionSetValues | 0:LocalizedText [] | 0:PropertyType | ||
| Conformance Units | ||||||
|---|---|---|---|---|---|---|
| DI AssetLocationIndication |
4.6 ComponentType
Compared to DeviceType the ComponentType is more universal. It includes the same components but does not mandate any Properties. This makes it usable for representation of a Device or parts of a Device. Parts include both mechanical and software parts.
The ComponentType applies the VendorNameplate and the TagNameplate Interface. Figure 9 Illustrates the ComponentType. It is formally defined in Table 34.
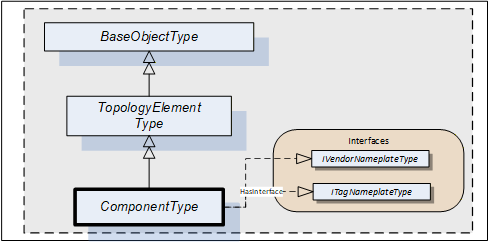
| Attribute | Value | ||||
| BrowseName | 1:ComponentType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the TopologyElementType defined in 4.3. | |||||
| HasSubtype | ObjectType | 1:DeviceType | Defined in 4.7. | ||
| HasSubtype | ObjectType | 1:SoftwareType | Defined in 4.8. | ||
| HasInterface | ObjectType | 1:IVendorNameplateType | Defined in 4.5.2. | ||
| HasInterface | ObjectType | 1:ITagNameplateType | Defined in 4.5.3. | ||
| Applied from IVendorNameplateType | |||||
| 0:HasProperty | Variable | 1:Manufacturer | 0:LocalizedText | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ManufacturerUri | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:Model | 0:LocalizedText | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ProductCode | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:HardwareRevision | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:SoftwareRevision | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:DeviceRevision | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:DeviceManual | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:DeviceClass | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:SerialNumber | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ProductInstanceUri | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:RevisionCounter | 0:Int32 | 0:PropertyType | O |
| Applied from ITagNameplateType | |||||
| 0:HasProperty | Variable | 1:AssetId | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ComponentName | 0:LocalizedText | 0:PropertyType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Information Model |
The ComponentType is abstract. DeviceType and SoftwareType are subtypes of ComponentType. There will be no instances of a ComponentType itself, only of concrete subtypes.
IVendorNameplateType and its members are described in 4.5.2.
ITagNameplateType and its members are described in 4.5.3.
4.7 DeviceType
This ObjectType can be used to define the structure of a Device. Figure 10 shows the DeviceType. It is formally defined in Table 35.
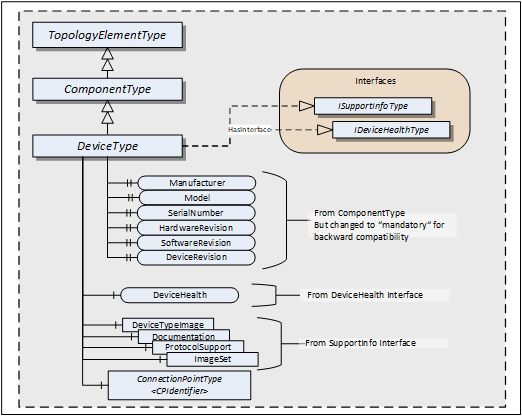
| Attribute | Value | ||||
| BrowseName | 1:DeviceType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the ComponentType defined in 4.5.7 | |||||
| HasInterface | ObjectType | 1:ISupportInfoType | Defined in 4.5.3. | ||
| HasInterface | ObjectType | 1:IDeviceHealthType | Defined in 4.5.3. | ||
| 0:HasComponent | Object | 1:<CPIdentifier> | 1:ConnectionPointType | OP | |
| 0:HasProperty | Variable | 1:SerialNumber | 0:String | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:RevisionCounter | 0:Int32 | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:Manufacturer | 0:LocalizedText | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:Model | 0:LocalizedText | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:DeviceManual | 0:String | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:DeviceRevision | 0:String | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:SoftwareRevision | 0:String | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:HardwareRevision | 0:String | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:DeviceClass | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ManufacturerUri | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ProductCode | 0:String | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ProductInstanceUri | 0:String | 0:PropertyType | O |
| Applied from IDeviceHealthType | |||||
| 0:HasComponent | Variable | 1:DeviceHealth | DeviceHealthEnumeration | 0:BaseDataVariableType | O |
| 0:HasComponent | Object | 1:DeviceHealthAlarms | 0:FolderType | O | |
| Applied from ISupportInfoType | |||||
| 0:HasComponent | Object | 1:DeviceTypeImage | 0:FolderType | O | |
| 0:HasComponent | Object | 1:Documentation | 0:FolderType | O | |
| 0:HasComponent | Object | 1:ProtocolSupport | 0:FolderType | O | |
| 0:HasComponent | Object | 1:ImageSet | 0:FolderType | O | |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI DeviceType |
DeviceType is a subtype of ComponentType which means it inherits all InstanceDeclarations.
The DeviceType ObjectType is abstract. There will be no instances of a DeviceType itself, only of concrete subtypes.
ConnectionPoints (see 5.4) represent the interface (interface card) of a DeviceType instance to a Network. Multiple ConnectionPoints can exist if multiple protocols and/or multiple Communication Profiles are supported.
The Interfaces and their members are described in 4.5. Some of the Properties inherited from the ComponentType are declared mandatory for backward compatibility.
Although mandatory, some of the Properties are not supported for certain types of Devices. In this case vendors shall provide the following defaults:
| Properties with DataType String: | empty string |
| Properties with DataType LocalizedText: | empty text field |
| RevisionCounter Property: | - 1 |
Clients can ignore the Properties when they have these defaults.
When Properties are not supported, Servers should initialize the corresponding Property declaration on the DeviceType with the default value. Relevant Browse Service requests can then return a Reference to this Property on the type definition. That way, no extra Nodes are required.
4.8 SoftwareType
This ObjectType can be used for software modules of a Device or a part of a Device. SoftwareType is a concrete subtype of ComponentType and can be used directly.
Figure 11 Illustrates the SoftwareType. It is formally defined in Table 36.
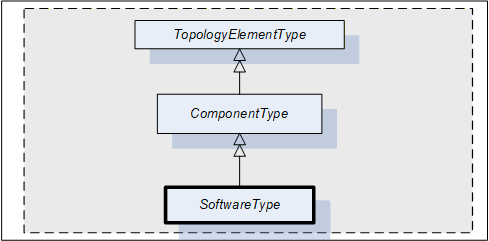
| Attribute | Value | ||||
| BrowseName | 1:SoftwareType | ||||
| IsAbstract | False | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the ComponentType defined in 4.5.7. | |||||
| 0:HasProperty | Variable | 1:Manufacturer | 0:LocalizedText | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:Model | 0:LocalizedText | 0:PropertyType | M |
| 0:HasProperty | Variable | 1:SoftwareRevision | 0:String | 0:PropertyType | M |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Software Component |
SoftwareType is a subtype of ComponentType which means it inherits all InstanceDeclarations.
The Properties Manufacturer, Model, and SoftwareRevision inherited from ComponentType are declared mandatory for SoftwareType instances.
4.9 DeviceSet entry point
The DeviceSet Object is the starting point to locate Devices. It shall either directly or indirectly reference all instances of a subtype of ComponentType with a Hierarchical Reference. For complex Devices that are composed of various components that are also Devices, only the root instance shall be referenced from the DeviceSet Object. The components of such complex Devices shall be locatable by following Hierarchical References from the root instance. An example is the Modular Device defined in 9.4 and also illustrated in Figure 12.
Examples:
UA Server represents a monolithic or modular Device: DeviceSet only contains one instance
UA Server represents a host system that has access to a number of Devices that it manages: DeviceSet contains several instances that the host provides access to.
UA Server represents a gateway Device that acts as representative for Devices that it has access to: DeviceSet contains the gateway Device instance and instances for the Devices that it represents.
UA Server represents a robotic system consisting of mechanics and controls. DeviceSet only contains the instance for the root of the robotic system. The mechanics and controls are represented by ComponentType instances which are organized as sub-components of the root instance.
Figure 12 shows the AddressSpace organisation with this standard entry point and examples.
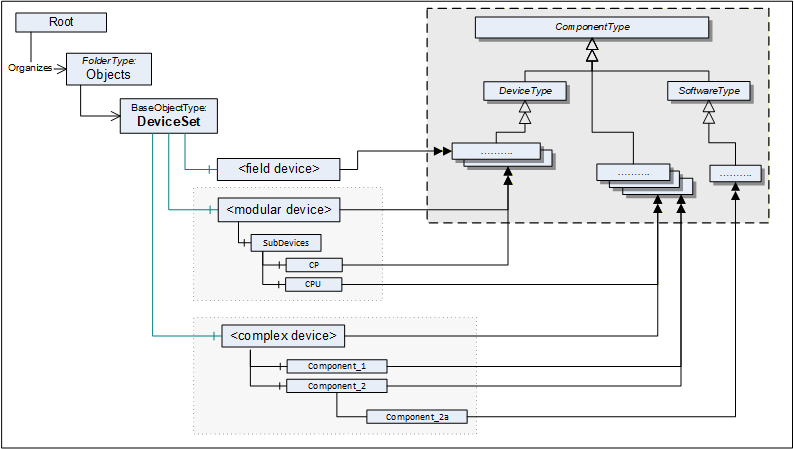
The DeviceSet Node is formally defined in Table 37.
| Attribute | Value | ||
| BrowseName | 1:DeviceSet | ||
| References | NodeClass | BrowseName | TypeDefinition |
|---|---|---|---|
| OrganizedBy by the 0:Objects Folder defined in OPC 10000-5 | |||
| 0:HasTypeDefinition | ObjectType | 0:BaseObjectType | |
| Conformance Units | |||
|---|---|---|---|
| DI DeviceSet |
4.10 DeviceFeatures entry point
The DeviceFeatures Object can be used to organize other functional entities that are related to the Devices referenced by the DeviceSet. Companion specifications can standardize such instances and their BrowseNames. Figure 13 shows the AddressSpace organisation with this standard entry point.
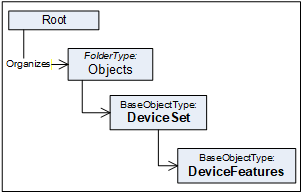
The DeviceFeatures Node is formally defined in Table 38.
| Attribute | Value | ||
| BrowseName | 1:DeviceFeatures | ||
| References | NodeClass | BrowseName | TypeDefinition |
|---|---|---|---|
| OrganizedBy by the DeviceSet Object defined in 4.9 | |||
| 0:HasTypeDefinition | ObjectType | 0:BaseObjectType | |
| Conformance Units | |||
|---|---|---|---|
| DI DeviceSet |
4.11 BlockType
This ObjectType defines the structure of a Block Object. Figure 14 depicts the BlockType hierarchy. It is formally defined in Table 39.
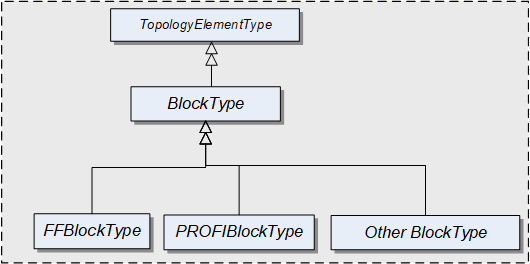
FFBlockType and PROFIBlockType are examples. They are not further defined in this specification. It is expected that industry groups will standardize general purpose BlockTypes.
| Attribute | Value | ||||
| BrowseName | 1:BlockType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the TopologyElementType defined in 4.2 | |||||
| 0:HasProperty | Variable | 1:RevisionCounter | 0:Int32 | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:ActualMode | 0:LocalizedText | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:PermittedMode | 0:LocalizedText [] | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:NormalMode | 0:LocalizedText [] | 0:PropertyType | O |
| 0:HasProperty | Variable | 1:TargetMode | 0:LocalizedText [] | 0:PropertyType | O |
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI Blocks |
BlockType is a subtype of TopologyElementType and inherits the elements for Parameters, Methods and FunctionalGroups.
The BlockType is abstract. There will be no instances of a BlockType itself, but there will be instances of subtypes of this Type. In this specification, the term Block generically refers to an instance of any subtype of the BlockType.
The RevisionCounter is an incremental counter indicating the number of times the static data within the Block has been modified. A value of -1 indicates that no revision information is available.
The following Properties refer to the BlockMode (e.g., "Manual", "Out of Service").
The ActualMode Property reflects the current mode of operation.
The PermittedMode defines the modes of operation that are allowed for the Block based on application requirements.
The NormalMode is the mode the Block should be set to during normal operating conditions. Depending on the Block configuration, multiple modes can exist.
The TargetMode indicates the mode of operation that is desired for the Block. Depending on the Block configuration, multiple modes can exist.
4.12 DeviceHealth Alarm Types
4.12.1 General
The DeviceHealth Property defined in 4.5.4 provides a basic way to expose the health state of a device based on NAMUR NE 107.
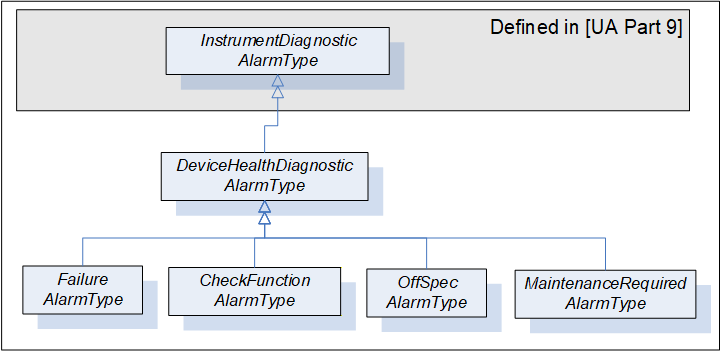
This section defines AlarmTypes that can be used to indicate an abnormal device condition together with diagnostic information text as defined by NAMUR NE 107 as well as additional manufacturer specific information.
Figure 15 informally describes the AlarmTypes for DeviceHealth.
4.12.2 DeviceHealthDiagnosticAlarmType
The DeviceHealthDiagnosticAlarmType is a specialization of the InstrumentDiagnosticAlarmType intended to represent abnormal device conditions as defined by NAMUR NE 107. This type can be used in filters for monitored items. Only subtypes of this type will be used in actual implementations. The Alarm becomes active when the device condition is abnormal. It is formally defined in Table 40.
| Attribute | Value | ||||
| BrowseName | 1:DeviceHealthDiagnosticAlarmType | ||||
| IsAbstract | True | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition |
Modelling
Rule |
|---|---|---|---|---|---|
| Subtype of the 0:InstrumentDiagnosticAlarmType defined in OPC 10000-9. | |||||
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI HealthDiagnosticsAlarm |
Conditions of subtypes of DeviceHealthDiagnosticAlarmType become active when the device enters the corresponding abnormal state.
The Message field in the Event notification shall be used for additional information associated with the health status (e.g. the possible cause of the abnormal state and suggested actions to return to normal).
A Device can be in more than one abnormal state at a time in which case multiple Conditions will be active.
4.12.3 FailureAlarmType
The FailureAlarmType is formally defined in Table 41. For description of the FAILURE state see Table 22.
| Attribute | Value | ||||
| BrowseName | 1:FailureAlarmType | ||||
| IsAbstract | False | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 1:DeviceHealthDiagnosticAlarmType defined in 4.12.2. | |||||
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI HealthDiagnosticsAlarm |
4.12.4 CheckFunctionAlarmType
The CheckFunctionAlarmType is formally defined in Table 42. For description of the CHECK_FUNCTION state see Table 22.
| Attribute | Value | ||||
| BrowseName | 1:CheckFunctionAlarmType | ||||
| IsAbstract | False | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 1:DeviceHealthDiagnosticAlarmType defined in 4.12.2. | |||||
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI HealthDiagnosticsAlarm |
4.12.5 OffSpecAlarmType
The OffSpecAlarmType is formally defined in Table 43. For description of the OFF_SPEC state see Table 22.
| Attribute | Value | ||||
| BrowseName | 1:OffSpecAlarmType | ||||
| IsAbstract | False | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 1:DeviceHealthDiagnosticAlarmType defined in 4.12.2. | |||||
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI HealthDiagnosticsAlarm |
4.12.6 MaintenanceRequiredAlarmType
The MaintenanceRequiredAlarmType is formally defined in Table 44. For description of the MAINTENANCE_REQUIRED state see Table 22.
| Attribute | Value | ||||
| BrowseName | 1:MaintenanceRequiredAlarmType | ||||
| IsAbstract | False | ||||
| References | NodeClass | BrowseName | DataType | TypeDefinition | Other |
|---|---|---|---|---|---|
| Subtype of the 1:DeviceHealthDiagnosticAlarmType defined in 4.12.2. | |||||
| Conformance Units | |||||
|---|---|---|---|---|---|
| DI HealthDiagnosticsAlarm |