
4 Concepts
4.1 General
This document defines an Information Model for Conditions, Dialog Conditions, and Alarms including acknowledgement capabilities. It is built upon and extends base Event handling which is defined in 10000-3, 10000-4 and 10000-5. This Information Model can also be extended to support the additional needs of specific domains. The details of what aspects of the Information Model are supported are defined via Profiles (see 10000-7 for Profile definitions). Some systems may expose historical Events and Conditions via the standard Historical Access framework (see 10000-11 for Historical Event definitions).
4.2 Conditions
Conditions are used to represent the state of a system or one of its components. Some common examples are:
a temperature exceeding a configured limit
a device needing maintenance
a batch process that requires a user to confirm some step in the process before proceeding
Each Condition instance is of a specific ConditionType. The ConditionType and derived types are sub-types of the BaseEventType (see 10000-3 and 10000-5). This part defines types that are common across many industries. It is expected that vendors or other standardisation groups will define additional ConditionTypes deriving from the common base types defined in this part. The ConditionTypes supported by a Server are exposed in the AddressSpace of the Server.
Condition instances are specific implementations of a ConditionType. It is up to the Server whether such instances are also exposed in the Server’s AddressSpace. Clause 4.10 provides additional background about Condition instances. Condition instances shall have a unique identifier to differentiate them from other instances. This is independent of whether they are exposed in the AddressSpace.
As mentioned above, Conditions represent the state of a system or one of its components. In certain cases, however, previous states that still need attention are also maintained. ConditionBranches are introduced to deal with this requirement and distinguish current state and previous states. Each ConditionBranch has a BranchId that differentiates it from other branches of the same Condition instance. The ConditionBranch which represents the current state of the Condition (the trunk) has a NULL BranchId. Servers can generate separate Event Notifications for each branch. When the state represented by a ConditionBranch does not need further attention, a final Event Notification for this branch will have the Retain Property set to False. Clause 5.5 provides more information and use cases. Maintaining previous states and therefore the support of multiple branches is optional for Servers.
Conceptually, the lifetime of the Condition instance is independent of its state. However, Servers may provide access to Condition instances only while ConditionBranches exist.
The base Condition state model is illustrated in Figure 1. It is extended by the various Condition subtypes defined in this document and may be further extended by vendors or other standardisation groups. The primary states of a Condition are disabled and enabled. The Disabled state is intended to allow Conditions to be turned off at the Server or below the Server (in a device or some underlying system). The Enabled state is normally extended with the addition of sub-states.
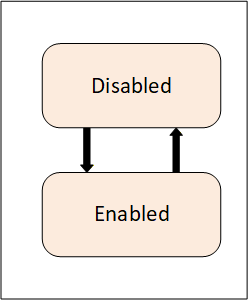
A transition into the Disabled state results in a Condition Event however no subsequent Event Notifications are generated until the Condition returns to the Enabled state.
ISA 18.2 and IEC 62682, which are the basis for this information model, no longer support enabling and disabling of alarms. As a result, even though this feature is still supported for backward compatibility it is recommended that alarms never be disabled.
When a Condition enters the Enabled state, that transition and all subsequent transitions result in Condition Events being generated by the Server.
If Auditing is supported by a Server, the following Auditing related action shall be performed. The Server will generate AuditEvents for Enable and Disable operations (either through a Method call or some Server / vendor – specific means), rather than generating an AuditEvent Notification for each Condition instance being enabled or disabled. For more information, see the definition of AuditConditionEnableEventType in 5.10.2. AuditEvents are also generated for any other Operator action that results in changes to the Conditions.
4.3 Acknowledgeable Conditions
AcknowledgeableConditions are sub-types of the base ConditionType. AcknowledgeableConditions expose states related to acknowledged or confirmed in a Condition.
An AckedState and a ConfirmedState extend the EnabledState defined by the Condition. The state model is illustrated in Figure 2. The enabled state is extended by adding the AckedState and (optionally) the ConfirmedState.
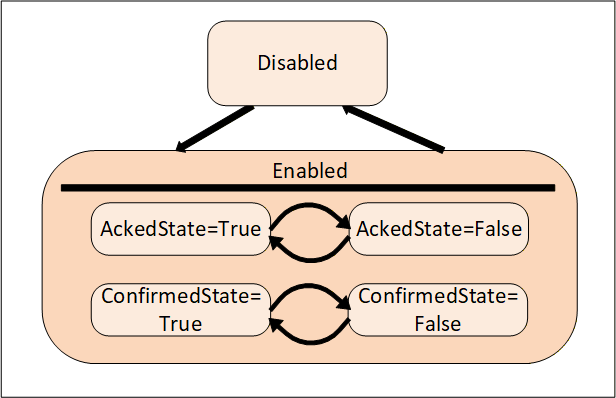
Acknowledgment of the transition may come from the Client or may be due to some logic internal to the Server. For example, acknowledgment of a related Condition may result in this Condition becoming acknowledged, or the Condition may be set up to automatically Acknowledge itself when the acknowledgeable situation disappears.
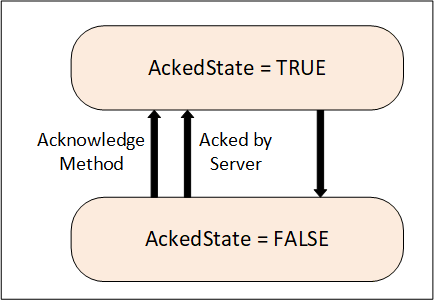
Two Acknowledge state models are supported by this document. Either of these state models can be extended to support more complex acknowledgement situations.
The basic Acknowledge state model is illustrated in Figure 3. This model defines an AckedState. The specific state changes that result in a change to the state depend on a Server’s implementation. For example, in typical Alarm models the change is limited to a transition to the Active state or transitions within the Active state. More complex models however can also allow for changes to the AckedState when the Condition transitions to an inactive state.
A more complex state model which adds a confirmation to the basic Acknowledge is illustrated in Figure 4. The Confirmed Acknowledge model is typically used to differentiate between acknowledging the presence of a Condition and having done something to address the Condition. For example, an Operator receiving a motor high temperature Notification calls the Acknowledge Method to inform the Server that the high temperature has been observed. The Operator then takes some action such as lowering the load on the motor in order to reduce the temperature. The Operator then calls the Confirm Method to inform the Server that a corrective action has been taken.
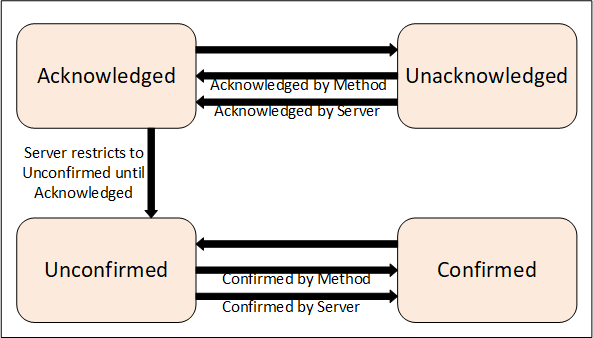
The AcknowledgeableConditions model can also be used for a simple Condition that requires a confirmation. For example, a motor start event is not an alarm, just an action that is to be acknowledged by the operator. It could also be an event that is generated for an operator change of a process input (grade of paper being made) that needs to be acknowledged. It is not something that requires an anwser like a question, for this there are DialogCondition. It is just an acknowledge that the operator observed the change.
4.4 Previous states of Conditions
Some systems require that previous states of a Condition are preserved for some time. A common use case is the acknowledgement process. In certain environments, it is required to acknowledge both the transition into Active state and the transition into an Inactive state. Systems with strict safety rules sometimes require that every transition into Active state is acknowledged. In situations where state changes occur in short succession there can be multiple unacknowledged states and the Server maintains ConditionBranches for all previous unacknowledged states. These branches will be deleted after they have been acknowledged or if they reached their final state.
Multiple ConditionBranches can also be used for other use cases where snapshots of previous states of a Condition require additional actions.
4.5 Condition state synchronization
When a Client subscribes for Events, the Notification of transitions will begin at the time of the Subscription. The currently existing state will not be reported. This means for example that Clients are not informed of currently Active Alarms until a new state change occurs.
Clients can obtain the current state of all Condition instances that are in an interesting state, by requesting a Refresh for a Subscription. It should be noted that Refresh is not a general replay capability since the Server is not required to maintain an Event history.
Clients request a Refresh by calling the ConditionRefresh Method. The Server will respond with a RefreshStartEventType Event. This Event is followed by the Retained Conditions. The Server may also send new Event Notifications interspersed with the Refresh related Event Notifications. After the Server is done with the Refresh, a RefreshEndEvent is issued marking the completion of the Refresh. Clients shall check for multiple Event Notifications for a ConditionBranch to avoid overwriting a new state delivered together with an older state from the Refresh process. If a ConditionBranch exists, then the current Condition shall be reported. This is True even if the only interesting item regarding the Condition is that ConditionBranches exist. This allows a Client to accurately represent the current Condition state.
A Client that wishes to display the current status of Alarms and Conditions (known as a “current Alarm display”) would use the following logic to process Refresh Event Notifications. The Client flags all Retained Conditions as suspect on reception of the Event of the RefreshStartEventType. The Client adds any new Events that are received during the Refresh without flagging them as suspect. The Client also removes the suspect flag from any Retained Conditions that are returned as part of the Refresh. When the Client receives a RefreshEndEvent, the Client removes any remaining suspect Events, since they no longer apply.
The following items should be noted with regard to ConditionRefresh:
As described in 4.4 some systems require that previous states of a Condition are preserved for some time. Some Servers – in particular if they require acknowledgement of previous states – will maintain separate ConditionBranches for prior states that still need attention.
ConditionRefresh shall issue Event Notifications for all interesting states (current and previous) of a Condition instance and Clients can therefore receive more than one Event for a Condition instance with different BranchIds.
It is possible under some circumstances a Server is not capable of ensuring the Client is fully in sync with the current state of Condition instances. For example, if the underlying system represented by the Server is reset or communications are lost for some period of time it can be necessary for the Server to resynchronize itself with the underlying system. In these cases, the Server sends an Event of the RefreshRequiredEventType to advise the Client that a Refresh may be necessary. A Client receiving this special Event should initiate a ConditionRefresh as noted in this clause.
To ensure a Client is always informed, the three special EventTypes (RefreshEndEventType, RefreshStartEventType and RefreshRequiredEventType) ignore the Event content filtering associated with a Subscription and will always be delivered to the Client.
ConditionRefresh applies to a Subscription. If multiple Event Notifiers are included in the same Subscription, all Event Notifiers are refreshed.
4.6 Severity, quality, and comment
Comment, Severity and Quality are important elements of Conditions and any change to them will cause Event Notifications.
The severity of a Condition is inherited from the base Event model defined in 10000-5. It indicates the urgency of the Condition and is also commonly called alarm priority or ‘priority’, especially in relation to Alarms in the ProcessConditionClassType. Severity is defined to have a range of 1-1000, but this range includes Alarms and other events that are not considered Alarms. For Alarms it is recommended that Severities above 400 be used. The 400-1000 range for Alarms should be further subdivided based on the severity of the Alarm. For an example of how Severity ranges are subdivided for diagnostics see 10000-26 LogRecord Severity Mapping.
A Comment is a user generated string that is associated with a certain state of a Condition.
Quality refers to the quality of the data value(s) upon which this Condition is based. Since a Condition is usually based on one or more Variables, the Condition inherits the quality of these Variables. E.g., if the process value is “Uncertain”, the “Level Alarm” Condition is also questionable. If more than one variable is represented by a given condition or if the condition is from an underlining system and no direct mapping to a variable is available, it is up to the application to determine what quality is displayed as part of the condition.
4.7 Dialogs
Dialogs are ConditionTypes used by a Server to request user input. They are typically used when a Server has entered some state that requires intervention by a Client. For example, a Server monitoring a paper machine indicates that a roll of paper has been wound and is ready for inspection. The Server would activate a Dialog Condition indicating to the user that an inspection is required. Once the inspection has taken place the user responds by informing the Server of an accepted or unaccepted inspection allowing the process to continue.
4.8 Alarms
Alarms are specializations of AcknowledgeableConditions that add the concepts of an Active state and other states like Shelving state and Suppressed state to a Condition. The state model is illustrated in Figure 5. The complete model with all states is defined in 5.8.
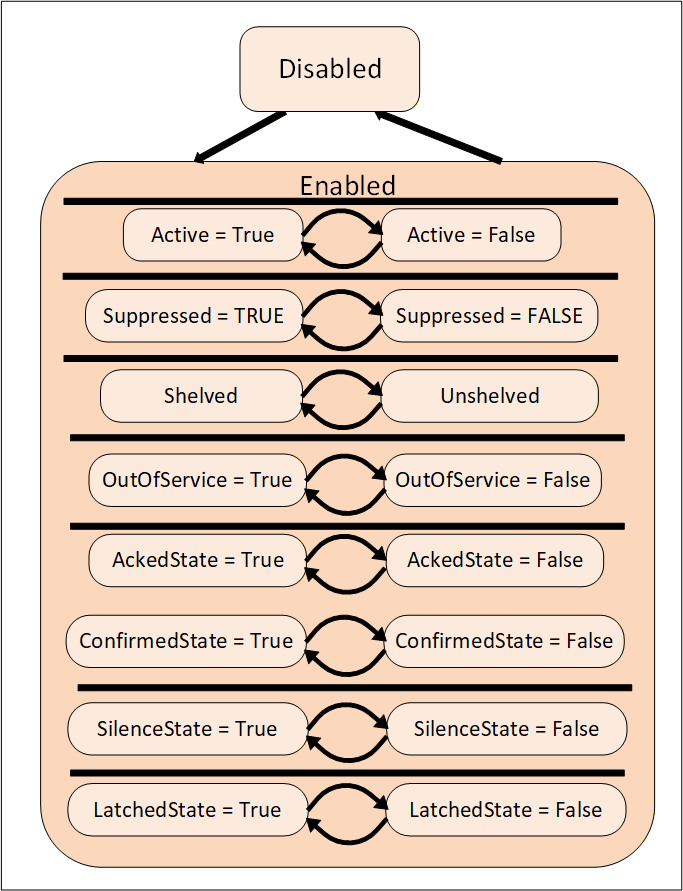
An Alarm in the Active state indicates that the situation the Condition is representing currently exists. When an Alarm is an inactive state it is representing a situation that has returned to a normal state.
Some Alarm subtypes introduce sub-states of the Active state. For example, an Alarm representing a temperature may provide a high level state as well as a critically high state (see following Clause).
The shelving state can be set by an Operator via OPC UA Methods. The suppressed state is set internally by the Server due to system specific reasons. Alarm systems typically implement the suppress, out of service and shelve features to help keep Operators from being overwhelmed during Alarm “storms” by limiting the number of Alarms an Operator sees on a current Alarm display. This is accomplished by setting the SuppressedOrShelved flag on second order dependent Alarms and/or Alarms of less severity, leading the Operator to concentrate on the most critical issues.
The LatchedState is a state that is added to any alarm that requires additional processing, once it goes active it does not clear until it is explicitly reset, even if the value that triggered the alarm returns to normal. This can be an alarm that requires a physical inspection once it has occurred to ensure it is no longer in alarm, or a series of tests that might be required to ensure the alarm is no longer active or some other actions. Any AlarmType can become a latched alarm by the addition of this optional sub-state.
The shelved, out of service and suppressed states differ from the Disabled state in that Alarms are still fully functional and can be included in Subscription Notifications to a Client. A disabled Alarm is not processed in any manner, and is not supported as part of the active Alarm model defined in ISA 18.2.
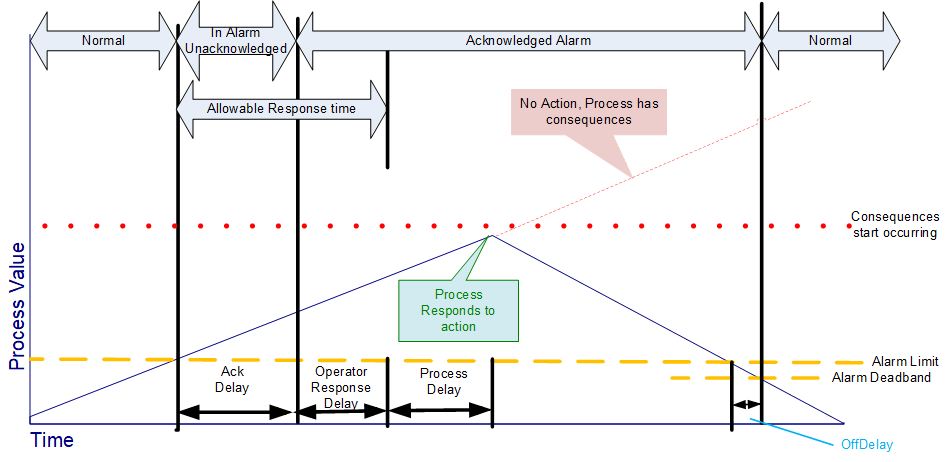
Alarms follow a typical timeline that is illustrated in Figure 6. They have a number of delay times associated with them and a number of states that they might occupy. The goal of an alarming system is to inform Operators about conditions in a timely manner and allow the Operator to take some action before some consequences occur. The consequences may be economic (product is not usable and is discard), may be physical (tank overflows), may safety (fire or explosion could occur) or any of a number of other possibilities. Typically, if no action is taken related to an alarm for some period of time the process will cross some threshold at which point consequences will start to occur. The OPC UA Alarm model describes these states, delays and actions.
4.9 Multiple active states
In some cases, it is desirable to further define the Active state of an Alarm by providing a sub-state machine for the Active State. For example, a multi-state level Alarm when in the Active state may be in one of the following sub-states: LowLow, Low, High or HighHigh. The state model is illustrated in Figure 7.
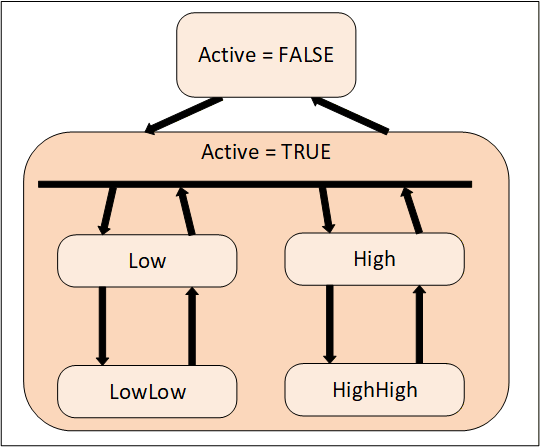
With the multi-state Alarm model, state transitions among the sub-states of Active are allowed without causing a transition out of the Active state.
To accommodate different use cases both a (mutually) exclusive and a non-exclusive model are supported.
Exclusive means that the Alarm can only be in one sub-state at a time. If for example a temperature exceeds the HighHigh limit the associated exclusive level Alarm will be in the HighHigh sub-state and not in the High sub-state.
Some Alarm systems, however, allow multiple sub-states to exist in parallel. This is called non-exclusive. In the previous example where the temperature exceeds the HighHigh limit a non-exclusive level Alarm will be both in the High and the HighHigh sub-state.
4.10 Condition instances in the AddressSpace
Because Conditions always have a state (Enabled or Disabled) and possibly many sub-states it makes sense to have instances of Conditions present in the AddressSpace. If the Server exposes Condition instances they usually will appear in the AddressSpace as components of the Objects that “own” them. For example, a temperature transmitter that has a built-in high temperature Alarm would appear in the AddressSpace as an instance of some temperature transmitter Object with a HasComponent Reference to an instance of a LimitAlarmType.
The availability of instances allows Data Access Clients to monitor the current Condition state by subscribing to the Attribute values of Variable Nodes. It is possible that the value of a node may not always correspond with the value that appears in the Event. The value could be more recent than the value in the Event.
While exposing Condition instances in the AddressSpace is not always possible, doing so allows for direct interaction (read, write and Method invocation) with a specific Condition instance. For example, if a Condition instance is not exposed, there is no way to invoke the Enable or Disable Method for the specific Condition instance.
4.11 Alarm and Condition auditing
The OPC UA Standards include provisions for auditing. Auditing is an important security and tracking concept. Audit records provide the “Who”, “When” and “What” information regarding user interactions with a system. These audit records are especially important when Alarm management is considered. Alarms are the typical instrument for providing information to a user that something needs the user’s attention. A record of how the user reacts to this information is required in many cases. Audit records are generated for all Method calls that affect the state of the system, for example, an Acknowledge Method call would generate an AuditConditionAcknowledgeEventType Event.
The standard AuditEventTypes defined in 10000-5 already include the fields required for Condition related audit records. To allow for filtering and grouping, this document defines a number of sub-types of the AuditEventTypes but without adding new fields to them.
This document describes the AuditEventType that each Method shall generate if Audit Events are supported by the Server. For example, the Disable Method has an AlwaysGeneratesEvent Reference to an AuditConditionEnableEventType. An Event of this type shall be generated for every invocation of the Method if audit events are supported. The audit Event describes the user interaction with the system, in some cases this interaction may affect more than one Condition or be related to more than one state.
4.12 Alarms in a system
In a system, alarms might be managed at different levels and by different applications. An alarm might be detected in an instrument, but the full alarm model for that alarm instance might be maintained in a higher level Server. This can cause issues in cases where the instrument is restarted or the UA Server that is acting as an alarm server is restarted. It is desirable that the state of alarms is maintained and that after any restart of either application all alarms recover their same state as before the restart. But it is acceptable if an alarm might require some management actions again following a restart. It is not acceptable that a device that is in alarm is no longer reported as being in alarm. For example, if the AlarmManager is restarted, when it recovers, can detect that the device has an alarm, but possibly not be able to recover that the alarm has a comment or that it was acknowledged. The individual Objects models provide details about Alarm states and recovery.