
4 General information to OPC 40560: OPC UA for Mining - General and OPC UA
4.1 Introduction to the OPC UA Companion Specification Mining
In the mining industry, the increasing demand for machine- and systems-level connectivity and interoperability has led to the requirement of communication protocols that are capable of standardized information exchange. OPC Unified Architecture allows to define instantiable, SDK-agnostic information models, thereby fulfilling this requirement. At its core, the OPC UA Companion Specification Mining provides type definitions for mining machines, equipment, systems and services. Making use of the object-oriented nature of OPC UA information models, similar mining machine and system type definitions may also inherit their common features, such as variables, objects, events etc., from parent types. Furthermore, OPC UA is capable of integrating horizontal (Machine-To-Machine) as well as vertical (Machine-To-Superordinate System) communication patterns and exchanges. An overview of the CS Mining document structure is given in Chapter 4.2. An overview of the OPC UA Companion Specification Mining Use Cases is provided in Chapter 5. These will be heavily extended in future revisions of this OPC UA Companion Specification.
4.2 Introduction to the OPC UA CS Mining Document Structure
This section briefly introduces the multi-level document structure of the OPC UA Companion Specification Mining. The multi-level document structure is shown Figure 1. From this figure it becomes apparent, that the companion specification’s structure follows a three-level hierarchy. Every document in this hierarchy corresponds to precisely one OPC UA information model. Notably, the document hierarchy reflects the direction of type inheritance in this companion specification. Examples of this inheritance pattern are given further below.
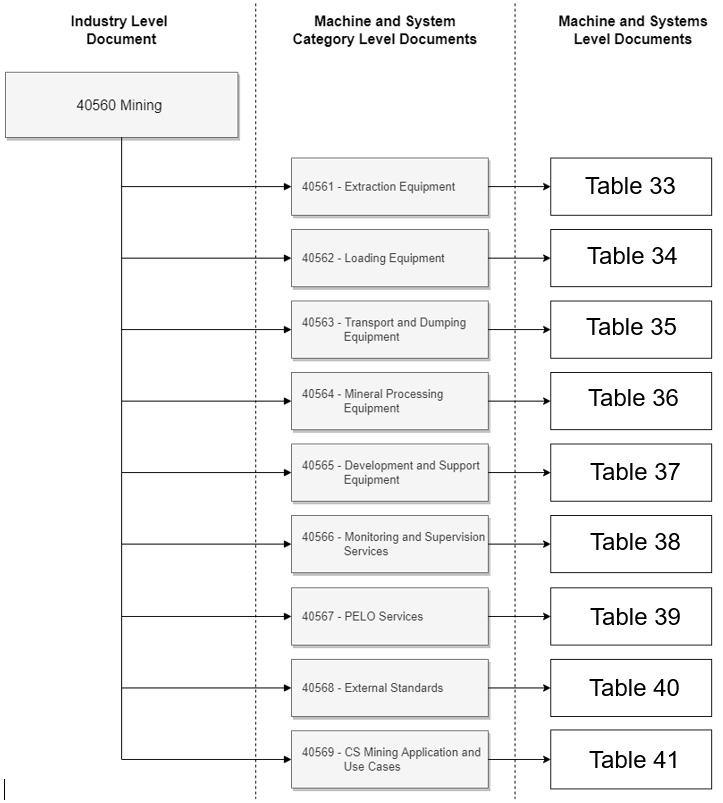
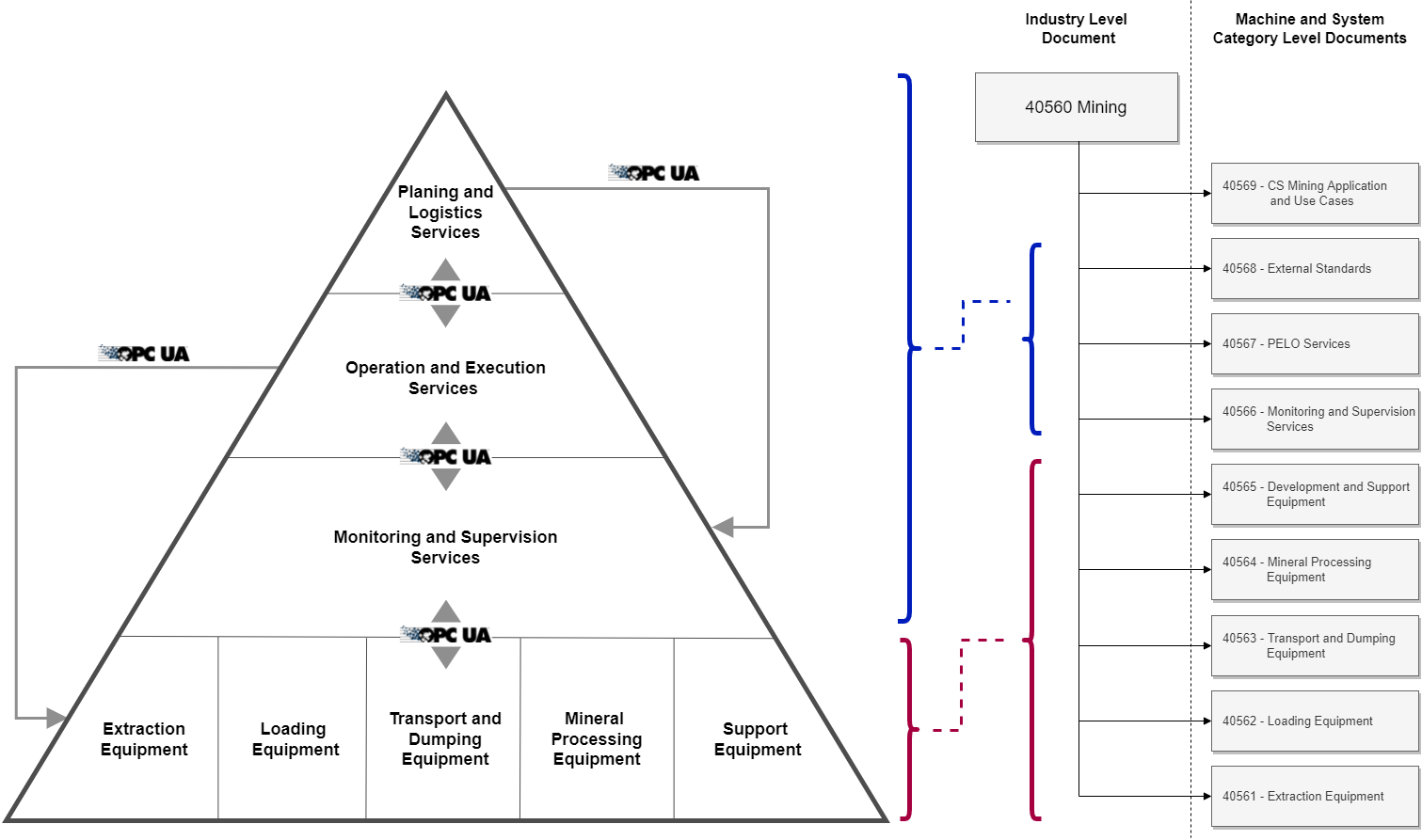
The document numbering of the OPC UA Companion Specification Mining ranges from 40560 to 40569. Parts 40561 to 40569 make use of a multi-part numbering scheme, meaning these documents consist of sub-parts. For example, part 40561-1 and 40561-2 are sub-parts of 40561. Furthermore, the parts 40561 to 40568 are used to classify similar type of mining machines and systems into disjunct groups which are structured regarding the core process steps of mining. The machines are integrated into this structure according to the main task performed by the machine. For instance, loading machines, such as hydraulic excavators or mining shovels, are classified to be sub-part documents of the OPC 40562 Loading Equipment multi-part document. Within the OPC UA Companion Specification Mining, there are nine such multi-part documents which are presented in Annex B as machine- and system-category-level documents. Figure 2 shows the relationship between the automation pyramid and the document structure, illustrating the possibility of integrating horizontal and vertical communication elements within the OPC UA Companion Specification Mining. The Numbering of the different machine level categories is based on the mining core process steps beginning with extraction.
By definition, the first sub-part of any multi-part document, e.g. OPC 40561-1, 40562-1 or 40567-1, serves as an introduction to a set of similar type of mining machinery or systems and therefore defines parent types common to all such machines and systems. For instance, the Hydraulic Excavator machine, as defined by the HydraulicExcavatorType in OPC 40562-2, makes use of some methods, variables etc. of a parent type, called LoadingMachineType, that is defined in the machine-category document OPC 40562-1. The Hydraulic Excavator is defined as loading equipment even if it is also used for extraction purposes. The main criteria of classification depend upon the main purpose of a machine, which is loading in case of the Hydraulic Excavator. An overview of the existing multi-part documents is provided in Annex B.
Following the same logic as above, the industry-level document OPC 40560 at the top of the hierarchy in Figure 1 defines terms, types and conventions used throughout and available to all subsequent machine-category- and machine-level documents. An example of this inheritance pattern is the abstract MiningEquipmentType, as defined in Chapter 7.1 of this document, which serves as a parent type for any machine-level types.
One exception to the above stated rules is OPC 40569 which describes the Application and Use Cases of the machines and systems covered in this Companion Specification.
4.3 Introduction to Security in the OPC UA CS Mining
As mentioned above, OPC UA offers state-of-the art security mechanisms to prevent information sent via the OPC UA protocol to become compromised. OPC 10000-2 describes security measures and possible attack vectors. As OPC UA is aiming to be used throughout all levels of automation, the need for a strict information security architecture becomes apparent.
Measures OPC UA takes to ensure the authenticity and authorization of client users to, e.g. read certain variables in an OPC UA Server, as well as measures to secure the confidentially of message exchange, i.e. to use encryption, are outlined in OPC 10000-2.
We strongly advise users of OPC UA Server and Client protocol implementations to check whether their chosen OPC UA protocol implementation complies with the measures mentioned in OPC 10000-2.
To alert users of the OPC UA CS Mining to security, we include Server and Client Security Profiles in all of our Information Models.
4.3.1 What is OPC UA?
OPC UA is an open and royalty free set of standards designed as a universal communication protocol. While there are numerous communication solutions available, OPC UA has key advantages:
A state of art security model (see OPC 10000-2).
A fault tolerant communication protocol.
An information modelling framework that allows application developers to represent their data in a way that makes sense to them.
OPC UA has a broad scope which delivers for economies of scale for application developers. This means that a larger number of high-quality applications at a reasonable cost are available. When combined with semantic models such as the ones defined in the OPC UA CS Mining, OPC UA makes it easier for end users to access data via generic commercial applications.
The OPC UA model is scalable from small devices to ERP systems. OPC UA Servers process information locally and then provide that data in a consistent format to any application requesting data - ERP, MES, PMS, Maintenance Systems, HMI, Smartphone or a standard Browser, for examples. For a more complete overview see OPC 10000-1.
4.3.2 Basics of OPC UA
As an open standard, OPC UA is based on standard internet technologies, like TCP/IP, HTTP, Web Sockets.
As an extensible standard, OPC UA provides a set of Services (see OPC 10000-4) and a basic information model framework. This framework provides an easy manner for creating and exposing vendor defined information in a standard way. More importantly all OPC UA Clients are expected to be able to discover and use vendor-defined information. This means OPC UA users can benefit from the economies of scale that come with generic visualization and historian applications. This specification is an example of an OPC UA Information Model designed to meet the needs of developers and users.
OPC UA Clients can be any consumer of data from another device on the network to browser based thin clients and ERP systems. The full scope of OPC UA applications is shown in Figure 3.
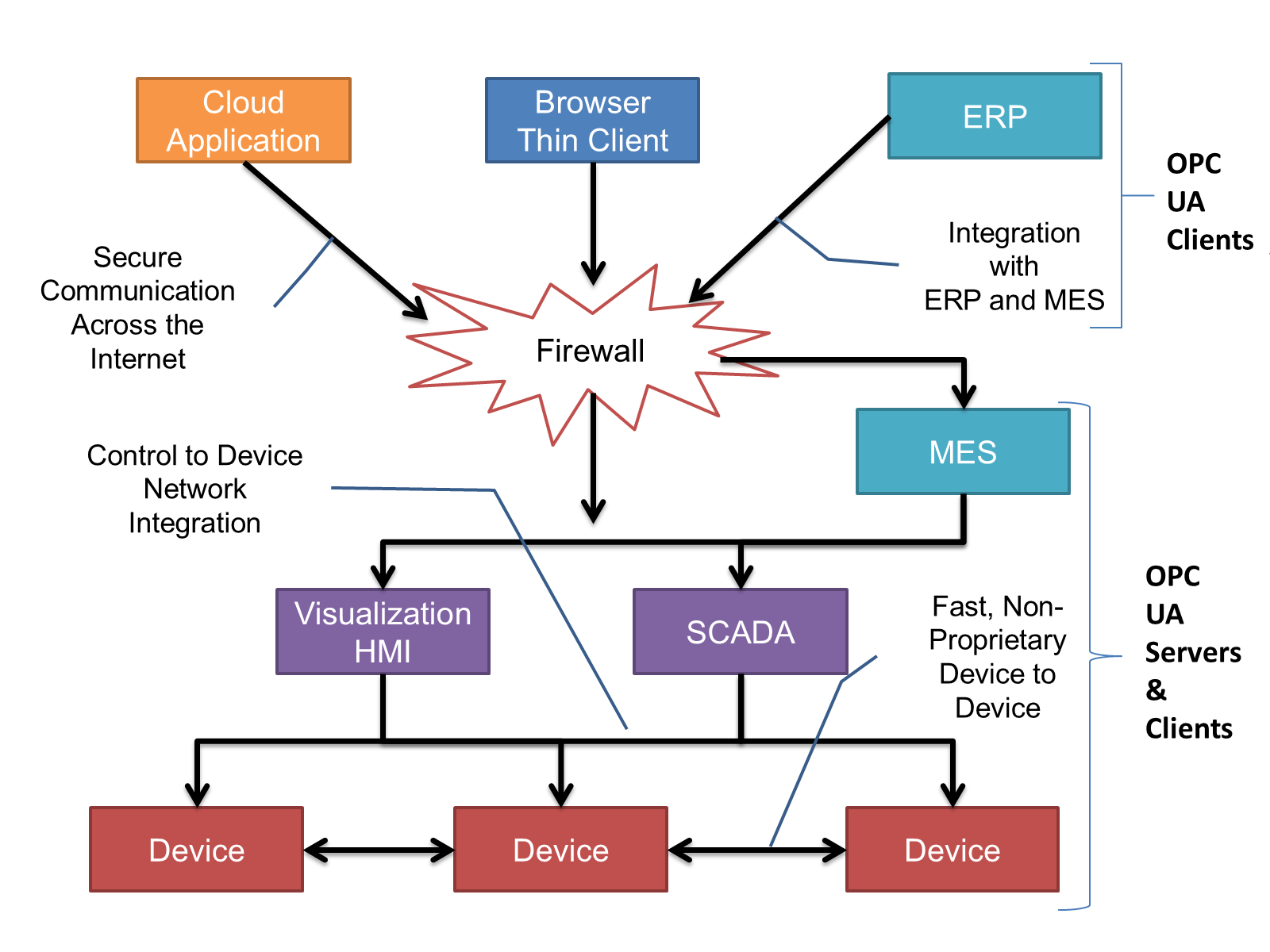
OPC UA provides a robust and reliable communication infrastructure having mechanisms for handling lost messages, failover, heartbeat, etc. With its binary encoded data, it offers a high-performing data exchange solution. Security is built into OPC UA as security requirements become more and more important especially since environments are connected to the office network or the internet and attackers are starting to focus on automation systems.
4.3.3 Information modelling in OPC UA
4.3.3.1 Concepts
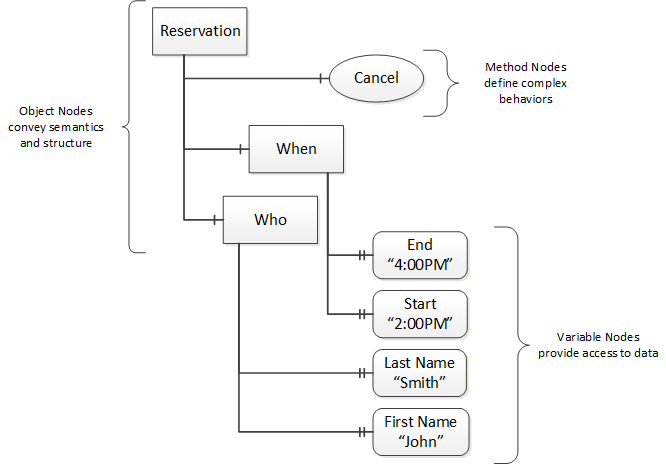
OPC UA provides a framework that can be used to represent complex information as Objects in an AddressSpace which can be accessed with standard services. These Objects consist of Nodes connected by References. Different classes of Nodes convey different semantics. For example, a Variable Node represents a value that can be read or written. The Variable Node has an associated DataType that can define the actual value, such as a string, float, structure etc. It can also describe the Variable value as a variant. A Method Node represents a function that can be called. Every Node has a number of Attributes including a unique identifier called a NodeId and non-localized name called as BrowseName. An Object representing a ‘Reservation’ is shown in Figure 4.
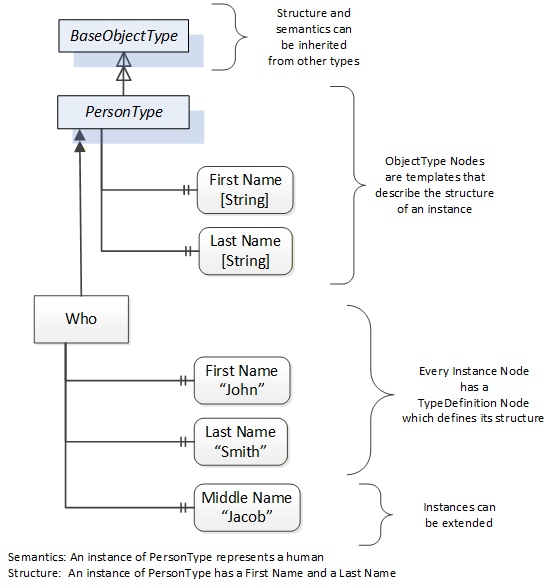
Object and Variable Nodes represent instances and they always reference a TypeDefinition (ObjectType or VariableType) Node which describes their semantics and structure. Figure 5 illustrates the relationship between an instance and its TypeDefinition.
The type Nodes are templates that define all of the children that can be present in an instance of the type. In the example in Figure 5 the PersonType ObjectType defines two children: First Name and Last Name. All instances of PersonType are expected to have the same children with the same BrowseNames. Within a type the BrowseNames uniquely identify the children. This means Client applications can be designed to search for children based on the BrowseNames from the type instead of NodeIds. This eliminates the need for manual reconfiguration of systems if a Client uses types that multiple Servers implement.
OPC UA also supports the concept of sub-typing. This allows a modeller to take an existing type and extend it. There are rules regarding sub-typing defined in OPC 10000-3, but in general they allow the extension of a given type or the restriction of a DataType. For example, the modeller may decide that the existing ObjectType in some cases needs an additional Variable. The modeller can create a subtype of the ObjectType and add the Variable. A Client that is expecting the parent type can treat the new type as if it was of the parent type. Regarding DataTypes, subtypes can only restrict. If a Variable is defined to have a numeric value, a sub type could restrict it to a float.
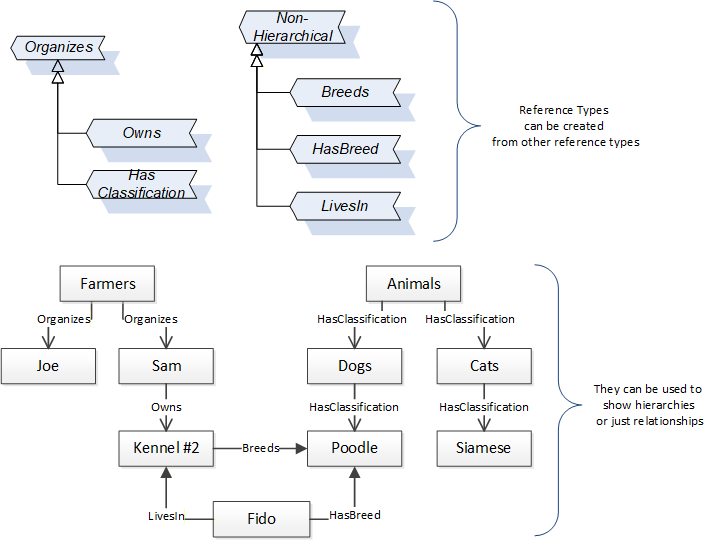
References allow Nodes to be connected in ways that describe their relationships. All References have a ReferenceType that specifies the semantics of the relationship. References can be hierarchical or non-hierarchical. Hierarchical references are used to create the structure of Objects and Variables. Non-hierarchical are used to create arbitrary associations. Applications can define their own ReferenceType by creating subtypes of an existing ReferenceType. Subtypes inherit the semantics of the parent but may add additional restrictions. Figure 6 depicts several References, connecting different Objects.
The figures above use a notation that was developed for the OPC UA specification. The notation is summarized in Figure 7. UML representations can also be used; however, the OPC UA notation is less ambiguous because there is a direct mapping from the elements in the figures to Nodes in the AddressSpace of an OPC UA Server.
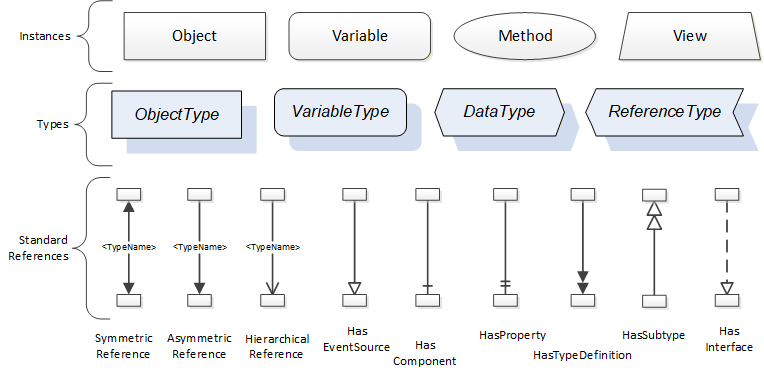
A complete description of the different types of Nodes and References can be found in OPC 10000-3 and the base structure is described in OPC 10000-5.
OPC UA specification defines a very wide range of functionality in its basic information model. It is not required that all Clients or Servers support all functionality in the OPC UA specifications. OPC UA includes the concept of Profiles, which segment the functionality into testable certifiable units. This allows the definition of functional subsets (that are expected to be implemented) within a companion specification. The Profiles do not restrict functionality, but generate requirements for a minimum set of functionality (see OPC 10000-7)
4.3.3.2 Namespaces
OPC UA allows information from many different sources to be combined into a single coherent AddressSpace. Namespaces are used to make this possible by eliminating naming and id conflicts between information from different sources. Each namespace in OPC UA has a globally unique string called a NamespaceUri which identifies a naming authority and a locally unique integer called a NamespaceIndex, which is an index into the Server's table of NamespaceUris. The NamespaceIndex is unique only within the context of a Session between an OPC UA Client and an OPC UA Server- the NamespaceIndex can change between Sessions and still identify the same item even though the NamespaceUri's location in the table has changed. The Services defined for OPC UA use the NamespaceIndex to specify the Namespace for qualified values.
There are two types of structured values in OPC UA that are qualified with NamespaceIndexes: NodeIds and QualifiedNames. NodeIds are locally unique (and sometimes globally unique) identifiers for Nodes. The same globally unique NodeId can be used as the identifier in a node in many Servers – the node's instance data may vary but its semantic meaning is the same regardless of the Server it appears in. This means Clients can have built-in knowledge of of what the data means in these Nodes. OPC UA Information Models generally define globally unique NodeIds for the TypeDefinitions defined by the Information Model.
QualifiedNames are non-localized names qualified with a Namespace. They are used for the BrowseNames of Nodes and allow the same names to be used by different information models without conflict. TypeDefinitions are not allowed to have children with duplicate BrowseNames; however, instances do not have that restriction.
4.3.3.3 Companion Specifications
An OPC UA companion specification for an industry specific vertical market describes an Information Model by defining ObjectTypes, VariableTypes, DataTypes and ReferenceTypes that represent the concepts used in the vertical market, and potentially also well-defined Objects as entry points into the AddressSpace.