
5 Data encoding
5.1 General
5.1.1 Overview
This document defines three DataEncodings: OPC UA Binary, OPC UA XML and OPC UA JSON. It describes how to construct Messages using each of these encodings.
5.1.2 Built-in Types
All OPC UA DataEncodings are based on rules that are defined for a standard set of built-in types. These built-in types are then used to construct structures, arrays and Messages. The built-in types are described in Table 1.
| ID | Name | Nullable | Default | Description |
|---|---|---|---|---|
| 1 | Boolean | No | false | A two-state logical value (true or false). |
| 2 | SByte | No | 0 | An integer value between -128 and 127 inclusive. |
| 3 | Byte | No | 0 | An integer value between 0 and 255 inclusive. |
| 4 | Int16 | No | 0 | An integer value between -32768 and 32767 inclusive. |
| 5 | UInt16 | No | 0 | An integer value between 0 and 65535 inclusive. |
| 6 | Int32 | No | 0 | An integer value between -2,147,483,648 and 2,147,483,647 inclusive. |
| 7 | UInt32 | No | 0 | An integer value between 0 and 4,294,967,295 inclusive. |
| 8 | Int64 | No | 0 | An integer value between -9,223,372,036,854,775,808 and 9,223,372,036,854,775,807 inclusive. |
| 9 | UInt64 | No | 0 | An integer value between 0 and 18,446,744,073,709,551,615 inclusive. |
| 10 | Float | No | 0 | An IEEE single precision (32 bit) floating-point value. |
| 11 | Double | No | 0 | An IEEE double precision (64 bit) floating-point value. |
| 12 | String | Yes | null | A sequence of Unicode characters. |
| 13 | DateTime | Yes | DateTime.MinValue (see 5.1.4) | An instance in time. |
| 14 | Guid | Yes | All zeros | A 16-byte value that can be used as a globally unique identifier. |
| 15 | ByteString | Yes | null | A sequence of octets. |
| 16 | XmlElement | Yes | null | A sequence of Unicode characters that is an XML element. This built-in type shall not have subtypes. |
| 17 | NodeId | Yes | i=0 (see 5.1.12) | An identifier for a node in the address space of an OPC UA Server. |
| 18 | ExpandedNodeId | Yes | i=0 (see 5.1.12). | A NodeId that allows the namespace URI to be specified instead of an index. |
| 19 | StatusCode | No | Good | A numeric identifier for an error or condition that is associated with a value or an operation. |
| 20 | QualifiedName | Yes | All fields set to default. | A name qualified by a namespace. |
| 21 | LocalizedText | Yes | All fields set to default. | Human readable text with an optional locale identifier. |
| 22 | ExtensionObject | Yes | All fields set to default. | A structure that contains an application specific data type that can be processed even if the receiver does not have knowledge of the DataType. |
| 23 | DataValue | Yes | All fields set to default. | A data value with an associated status code and timestamps. |
| 24 | Variant | Yes | Null | A union of all of the types specified above. |
| 25 | DiagnosticInfo | Yes | No fields specified. | A structure that contains detailed error and diagnostic information associated with a StatusCode. |
Most of these data types are the same as the abstract types defined in OPC 10000-3 and OPC 10000-4. However, the ExtensionObject and Variant types are defined in this document. In addition, this document defines a representation for the Guid type defined in OPC 10000-3.
The Nullable column indicates whether a 'null' value exists for the DataType in all DataEncodings. A 'null' value is a value that is equivalent 'no value specified'. A nullable type with a default value means the default value shall be interpreted equivalent to a null.
The Default column specifies the default value for the type. The default value for all arrays is 'null'.
5.1.3 Guid
A Guid is a 16-byte globally unique identifier with the layout shown in Table 2.
| Component | Data Type |
|---|---|
| Data1 | UInt32 |
| Data2 | UInt16 |
| Data3 | UInt16 |
| Data4 | Byte [8] |
Guid values are represented as a string in this form:
<Data1>-<Data2>-<Data3>-<Data4[0:1]>-<Data4[2:7]>where Data1 is 8 characters wide, Data2 and Data3 are 4 characters wide and each Byte in Data4 is 2 characters wide. Each value is formatted as a hexadecimal number with padded zeros. A typical Guid value would look like this when formatted as a string:
C496578A-0DFE-4B8F-870A-745238C6AEAE
5.1.4 DateTime
DateTime values have different ranges on different DevelopmentPlatforms. To ensure interoperability two named values are defined:
"DateTime.MinValue" is the earliest value that can be represented;
"DateTime.MaxValue" is the latest value that can be represented.
If the range supported by the DataEncoding is outside of the range supported by a DevelopmentPlatform then decoders shall replace any below range values with DateTime.MinValue and any above range values with DateTime.MaxValue for the DevelopmentPlatform.
If the range supported by a DevelopmentPlatform is outside of the range supported by a DataEncoding then encoders shall replace any below range values with DateTime.MinValue and any above range values with DateTime.MaxValue for the DataEncoding.
The representation of a DateTime on a DevelopmentPlatform also has a maximum precision. Decoders shall truncate DateTime values that exceed the supported precision. All DevelopmentPlatforms shall support a precision of at least 1 ms.
The DataValue built-in type adds additional fields for Picoseconds. If a DevelopmentPlatform cannot support the full precision of DateTime values allowed by the DataEncoding then it should expand the size of its internal representation of Picoseconds field to preserve the full precision of the DateTime. If it does not do this it shall set the Picoseconds to 0.
The Picoseconds shall be set to 0 when the DateTime value is DateTime.MinValue or DateTime.MaxValue.
DateTime values shall be encoded as UTC values. If the source of the value uses a different time zone, the encoder shall convert to UTC. When a DataEncoding supports time zones other that UTC (e.g. XML), decoders shall convert to UTC.
Concrete examples can be found in 5.2.2.5.
5.1.5 ByteString
A ByteString is structurally the same as a one-dimensional array of Byte. It is represented as a distinct built-in data type because it allows encoders to optimize the transmission of the value. However, some DevelopmentPlatforms will not be able to preserve the distinction between a ByteString and a one-dimensional array of Byte.
If a decoder for DevelopmentPlatform cannot preserve the distinction it shall convert all one-dimensional arrays of Byte to ByteStrings.
Each element in a one-dimensional array of ByteString can have a different length which means is structurally different from a two-dimensional array of Byte where the length of each dimension is the same. This means decoders shall preserve the distinction between two or more-dimension arrays of Byte and one or more-dimension arrays of ByteString.
If a DevelopmentPlatform does not support unsigned integers, then it will have to represent ByteStrings as arrays of SByte. In this case, the requirements for Byte would then apply to SByte.
5.1.6 Number, Integer and UInteger
Number, Integer and UInteger are abstract simple types defined in OPC 10000-3. When these types are used in Structure fields, the field value is encoded as a Variant.
5.1.7 Structures and Unions
Structures are sequences of name value pairs defined by the DataTypeDefinition Attribute in OPC 10000-3. Each DataEncoding describes how to use the DataTypeDefinition to serialize Structures. Subtypes of Structure extend the parent by adding additional name-value pairs to the sequence.
If a DataTypeDefinition sets the StructureType to StructureWithSubtypedValues then any field with a subtype of Structure DataType and IsOptional=TRUE allows the type and any subtype of the field's DataType to be present in the field. In these cases, the values are serialized as an ExtensionObject. If IsOptional=FALSE then the field value is encoded directly according to the rules for the DataEncoding. Note that the StructureField IsOptional flag has an overloaded meaning because it was not possible to add an AllowSubtypes flag to StructureField and preserve backward compatibility. The value StructureType indicates how the IsOptional field is to be interpreted.
A field is serialized as an ExtensionObject if a field has a DataType set explicitly to Structure.
Unions are special subtypes of Structure where only one field value is encoded. All subtypes of Union are concrete. The remainder of the rules for Structure also apply to Unions.
5.1.8 ExtensionObject
An ExtensionObject is a container for any Structure and Union DataTypes.
The ExtensionObject contains a complex value serialized as a sequence of other DataTypes. It also contains an identifier which indicates what data it contains and how it is encoded.
There are four primary use cases where ExtensionObjects appear:
When encoding a top-level DataType as a Service Request or Response;
When encoding a Structure value inside a Variant;
When encoding a field value in a Structure where the field DataType is Structure.
When encoding a field value in a Structure where AllowSubTypes=TRUE (see F.12).
In all of these cases, the ExtensionObject provides an identifier that allows a decoder to know if it understands the Structure contained with it and a length that allows the Structure to be skipped if it is not recognized.
Structured DataTypes are represented in a Server address space as sub-types of the Structure DataType. The DataEncodings available for any given Structured DataTypes are represented as a DataTypeEncoding Object in the Server AddressSpace. The NodeId for the DataTypeEncoding Object is the identifier stored in the ExtensionObject. OPC 10000-3 describes how DataTypeEncoding Nodes are related to other Nodes of the AddressSpace.
Elements of an array of ExtensionObjects can have different DataTypeEncoding NodeIds specified. In some cases, this will be invalid, however, it is the responsibility of the application layer to enforce whatever constraints are imposed by the Information Model on a given array. Decoders shall accept any valid ExtensionObject as an array element.
Server implementers should use namespace qualified numeric NodeIds for any DataTypeEncoding Objects they define. This will minimize the overhead introduced by packing Structured DataType values into an ExtensionObject.
ExtensionObjects and Variants allow unlimited nesting which could result in stack overflow errors even if the message size is less than the maximum allowed. Decoders shall support at least 100 nesting levels. Decoders shall report an error if the number of nesting levels exceeds what it supports.
5.1.9 Variant
A Variant is a union of all built-in data types including an ExtensionObject. Variants can also contain arrays of any of these built-in types. Variants are used to store any value or parameter with a data type of BaseDataType or one of its subtypes.
Variants can be empty. An empty Variant is described as having a null value and should be treated like a null column in a SQL database. A null value in a Variant may not be the same as a null value for data types that support nulls such as Strings. Some DevelopmentPlatforms may not be able to preserve the distinction between a null for a DataType and a null for a Variant, therefore, applications shall not rely on this distinction. This requirement also means that if an Attribute supports the writing of a null value it shall also support writing of an empty Variant and vice versa.
Variants can contain arrays of Variants but they cannot directly contain another Variant.
DiagnosticInfo types only have meaning when returned in a response message with an associated StatusCode and table of strings. As a result, Variants cannot contain instances of DiagnosticInfo.
Values of Attributes are always returned in instances of DataValues. Therefore, the DataType of an Attribute cannot be a DataValue. Variants can contain DataValue when used in other contexts such as Method Arguments or PubSub Messages. The Variant in a DataValue cannot, directly or indirectly, contain another DataValue.
ExtensionObjects and Variants allow unlimited nesting which could result in stack overflow errors even if the message size is less than the maximum allowed. Decoders shall support at least 100 nesting levels. Decoders shall report an error if the number of nesting levels exceeds what it supports.
5.1.10 Decimal
A Decimal is a high-precision signed decimal number. It consists of an arbitrary precision integer unscaled value and an integer scale. The scale is the inverse power of ten that is applied to the unscaled value.
A Decimal has the fields described in Table 3.
| Field | Type | Description |
|---|---|---|
| TypeId | NodeId | The identifier for the Decimal DataType. |
| Encoding | Byte | This value is always 1. |
| Length | Int32 | The length of the Scale and Value fields in bytes. If the length is less than or equal to 2 then the Decimal is an invalid value that cannot be used. |
| Scale | Int16 | A signed integer representing scale which is the inverse power of ten that is applied to the unscaled value, The integer is encoded starting with the least significant bit. |
| Value | OctetString | A 2-complement signed integer representing the unscaled value. The number of bytes is the value of the Length field minus size of the Scale field. The integer is encoded with the least significant byte first. |
When a Decimal is encoded in a Variant the built-in type is set to ExtensionObject. Decoders that do not understand the Decimal type shall treat it like any other unknown Structure and pass it on to the application. Decoders that do understand the Decimal can parse the value and use any construct that is suitable for the DevelopmentPlatform. Note that a Decimal is like a built-in type and a DevelopmentPlatform has to have hardcoded knowledge of the type. No Structure metadata is published for this type.
If a Decimal is embedded in another Structure then the DataTypeDefinition for the field shall specify the NodeId of the Decimal Node as the DataType. If a Server publishes an OPC Binary type description for the Structure then the type description shall set the DataType for the field to ExtensionObject.
5.1.11 Null, Empty and Zero-Length Arrays
The terms null, empty and zero-length are used to describe array values (Strings are arrays of characters and ByteStrings are arrays of Bytes for purposes of this discussion). A null array has no value. A zero-length or empty array is an array with 0 elements. Some DataEncodings will allow the distinction to be preserved on the wire, however, not all DevelopmentPlatforms will be able to preserve the distinction. For this reason, null, empty and zero length arrays are semantically the same for all DataEncodings. Decoders shall be able to handle all variations supported by the DataEncoding, however, decoders are not required to preserve the distinction. When testing for equality, applications shall treat null and empty arrays as equal. When a DevelopmentPlatform supports the distinction, writing and reading back an array value can result in null array becoming an empty array or vice versa.
5.1.12 QualifiedName, NodeId and ExpandedNodeId String Encoding
QualifiedNames, NodeIds and ExpandedNodeIds optimize representation of NamespaceUris by using a NamespaceIndex to reference the location of the URI in a NamespaceTable. The NamespaceTable to use is known from the context. For example, when a Client establishes a Session with a Server, the Server supplies the NamespaceTable that is used for all exchanges within that Session. Another example, is when a Publisher publishes DataSetMetadata messages, the NamespaceTable is provided as part of the message.
However, there are other scenarios where there is no obvious context that can be used to store the NamespaceTable, such as column in a database table, so it is necessary to provide a self-contained representation of these DataTypes. This clause defines a normative String representation using the ABNF like notation (see IETF RFC 5234). Table 4 defines additional core rules used in these definitions.
| UNICODE | Any Unicode character other than a Control character. |
| CONTROL | Any Unicode Control character (includes nulls, carriage returns, tabs and new lines). |
| URI | A string that conforms to IETF RFC 3986. |
| ENCODEDURI | A URI which has the IETF RFC 3986 percent-encoding applied to it. Any ';' in the URI shall be percent encoded. |
| BASE64 | A Base64 encoded binary value (see Base64). |
The description for a NodeId is found in Table 5.
| <node-id> | = <identifier> |
| <node-id> | =/ <namespace-index> ";" <identifier> |
| <node-id> | =/ <namespace-uri> ";" <identifier> |
| <namespace-index> | = "ns=" 1*DIGIT |
| <namespace-uri> | = "nsu=" ENCODEDURI |
| <identifier> | = <numericid> / <stringid> / <guidid> / <opaqueid> |
| <numericid> | = "i=" *DIGIT |
| <stringid> | = "s=" *(UNICODE) |
| <guidid> | = "g=" 8HEXDIG 3("-" 4HEXDIG) "-" 12HEXDIG |
| <opaqueid> | = "b=" BASE64 |
NodeIds with a NamespaceIndex of 0 or a NamespaceUri of http://opcfoundation.org/UA/ shall only use the <identifier> form.
OPC 10000-3 prohibits control characters, such as tabs (U+0009), in the string identifier for NodeIds.
The URI portion of NodeIds are escaped with URI percent-encoding as defined in IETF RFC 3986. Semicolons are added to the list of reserved characters of all URI schemes.
Examples of NodeIds:
i=13
ns=10;i=12345
nsu=http://widgets.com/schemas/hello;s=水 World
g=09087e75-8e5e-499b-954f-f2a9603db28a
nsu=tag:acme.com,2023:schemas:data#off%3B;b=M/RbKBsRVkePCePcx24oRA==
The description for a ExpandedNodeId is found in Table 6.
| <expanded-node-id> | = <node-id> |
| <expanded-node-id> | =/ <server-index> ";" <node-id> |
| <expanded-node-id> | =/ <server-uri> ";" <node-id> |
| <server-index> | = "svr=" *DIGIT |
| <server-uri> | = "svu=" ENCODEDURI |
ExpandedNodeIds that are not specific to a Server shall use the <node-id> form.
OPC 10000-3 prohibits control characters, such as tabs (0x09), in the string identifier for ExpandedNodeIds.
The URI portions of ExpandedNodeIds are escaped with URI percent-encoding as defined in IETF RFC 3986. Semicolons are added to the list of reserved characters of all URI schemes.Examples of ExpandedNodeIds:
i=13
svr=1;nsu=http://widgets.com/schemas/hello;s=水 World
svu=http://smith.com/east/factory;g=09087e75-8e5e-499b-954f-f2a9603db28a
svu=http://smith.com/west/factory;nsu=tag:acme.com,2023:schemas:data#off%3B;b=M/RbKBsRVkePCePcx24oRA==
The description for a QualifiedName is found in Table 7.
| <qualified-name> | = <name> |
| <qualified-name> | =/ <short-index> ":" <name> |
| <qualified-name> | =/ <namespace-uri> ";" <name> |
| <name> | = 1*(UNICODE) |
| <short-index> | = 1*DIGIT |
QualifiedNames in the OPC UA Namespace shall not use the form with a <namespace-uri>.
The form without a prefix (the first row in Table 7) shall only be used for QualifiedNames in the OPC UA Namespace. This is unambiguous because the Name portion of a QualifiedName in the OPC UA Namespace starting with a sequence of digits followed by a colon is prohibited.
The <short-index> is the NamespaceIndex and is only used for QualifiedNames not in the OPC UA Namespace in contexts when NamespaceIndexes are allowed.
OPC 10000-3 prohibits control characters, such as tabs (0x09), in the name portion of a QualifiedName.
The URI portions of QualifiedNames are escaped with URI percent-encoding as defined in IETF RFC 3986. Semicolons are added to the list of reserved characters of all URI schemes.Examples of QualifiedNames:
InputArguments
3:Hello:World
nsu=http://widgets.com/schemas/hello;Hello;World
nsu=tag:acme.com,2023:schemas:data#off%3B;Boiler2
5.1.13 Name Encoding Rules
Text based DataEncodings such as UA XML (5.3) or UA JSON (5.4) make use of Names from the DataType and DataTypeDefinition to create the serialized data. XML and JSON formats impose restrictions on the Strings that are used in serialized data so it is necessary to define a transformation that ensures any Names can be used in the DataEncoding. The following rules are used to convert a DataType Name or a Structure Field Name to a string supported by the Encoding:
Any character that is not permitted by the DataEncoding is replaced by an underscore (U+005F);
A name with text sequence that is not valid in the first position has an underscore (U+005F) added as a prefix.
The character restrictions for the XML DataEncoding are:
| <allowed-name> | = <letter> *(<allowed-char> / "_" / "-"/ ".") |
| <allowed-char> | = <letter> / DIGIT |
| <letter> | = UNICODE-LETTER |
| UNICODE-LETTER | Any Unicode character with a general category of 'Letter' |
In addition, XML names cannot start with the text 'xml' or any variation in case (i.e. 'xMl').
There are no restrictions for the JSON encoding other than the general restrictions defined in OPC 10000-3.
Table 8 has examples of XML encoded names.
Hello
|
Hello
|
_Hello
|
_Hello
|
3DHello
|
_3DHello
|
冷水
|
冷水
|
3 (冷水。)-Hello
|
_3__冷水__-Hello
|
Note the last example includes a Japanese period that is not permitted by XML rules. The glyph for the Japanese period has trailing white space embedded in it. All characters not allowed by XML rules are replaced with underscores.
5.1.14 Structure FieldPath Encoding Rules
Values of Structure DataTypes are sequences of name-value pairs. In many cases the value will be an array or another Structure. There are situations where it is necessary to refer to an element within a Structure. The Structure FieldPath defines a path to a single value within a Structure.
The description for a Structure FieldPath is found in Table 9.
| <path> | = <path-element> *("." <path-element>) |
| <path-element> | = <name> / <index> |
| <name> | = 1*<char> / "'" 1*<char> "'" |
| <index> | = "[" 1*DIGIT *("," 1*DIGIT) "]" |
| <char> | = UNICODE-NO-CONTROL-OR-ESCAPED / <escaped> |
| <escaped> | = ".." / "[[" |
The UNICODE-NO-CONTROL-OR-ESCAPED is a core rule that includes all UNICODE characters except for U+0027 (') and any character with a category of Cc (control codes).
Any apostrophe (U+0027 (')) in a <name> is escaped by adding an extra copy of the same character and the name shall be enclosed with apostrophes.
Any <name> may be enclosed with apostrophes. Any <name> that contains U+0027 ('), U+005B ([), U+005B (]), or U+002E (.) shall be enclosed with apostrophes.
The <name> comes from the Name of a field in the DataTypeDefinition for the Structure.
The <index> is an index in field containing an array value. If an array has multiple dimensions, then the <index> has multiple elements separated by U+002C (,).
The DataTypeDefinition for a simple Structure is found in Table 10.
| Field Name | DataType | Description |
|---|---|---|
| Red | Boolean | Simple Boolean value. |
| Yellow.One | Int32 | Int32 value with a special character in the name. |
| Green's | String [] | Array of string values. |
The value for the simple Structure using JSON:
{
"Red": true,
"Yellow.One": 42,
"Green's": [ "macintosh", "fuji", "ambrosia" ]}
Examples of FieldPaths and their values based on the simple Structure value are in Table 11.
| FieldPath | Resolved Value |
|---|---|
| 'Yellow.One' | 42 |
| 'Green''s' | ["macintosh", "fuji", "ambrosia"] |
| 'Green''s'.[1] | "fuji" |
| Pink | Cannot be resolved because name not found. |
| 'Green''s'.[6] | Cannot be resolved because of index too large. |
| 'Green''s'.[TEXT] | Cannot be resolved because of non-numeric index. |
The DataTypeDefinition for a complex Structure is found in Table 12.
| Field Name | DataType | Description |
|---|---|---|
| Apple | SimpleStructure [] | An array of the Structure defined in Table 10. |
| [Banana] | Structure | Any Structure value. |
| Grape | BaseDataType | Any value. |
The value for the complex Structure using JSON:
{
"Apple": [
{
"Red": true,
"Yellow.One": 42,
"Green's": [ "macintosh", "fuji", "ambrosia" ]}
],
"[Banana]": {
"TypeId": "<type-id>",
"Body": {
"X": 987,
"Y": 432
},
"Grape": {
"Type": 6
"Body": [ 123, 345, 678 ]
},
}Examples of FieldPaths and their values based on the complex Structure value are in Table 13.
| FieldPath | Resolved Value |
|---|---|
| Apple.[0] | { "Red": true, "Yellow.One": 42, "Green": [ "macintosh", "fuji", "ambrosia" ] } |
| Apple.[0].'Yellow.One' | 42 |
| Apple.[0].'Green''s' | ["macintosh", "fuji", "ambrosia"] |
| Apple.[0].'Green''s'.[1] | "fuji" |
| '[Banana]' | { "TypeId": "<type-id>", "Body": { "X": 987, "Y": 432 } } |
| '[Banana]'.Body | { "X": 987, "Y": 432 } |
| '[Banana]'.Body.Y | 432 |
| Grape | { "Type": 6 "Body": [ 123, 345, 678 ] } |
| Grape.Body.[1] | 345 |
5.1.15 Messages
Messages are the top-level Structures exchanged between a Client and Server. A Message sent from a Client to a Server is a Request. A Message sent back to a Client from the Server is a Response.
Sending the same Message multiple times (i.e. calling Read ServerState over and over) increases the attack surface. To reduce the attack surface, any Messages can include random data inserted into the AdditionalHeader field of the RequestHeader or ResponseHeader. The key name for this random data is specified in Table 14.
| Name | DataType | Description |
|---|---|---|
| Padding | ByteString | Provides random padding that varies the sizes of Messages. The length is random number of bytes from 0 to 128. The value should be a sequence random bytes that are used for exactly one Message. |
The Padding should only be used over SecureChannels with a SecurityMode of SignAndEncrypt. The content of the Padding is ignored.
5.2 OPC UA Binary
5.2.1 General
The OPC UA Binary DataEncoding is a data format developed to meet the performance needs of OPC UA applications. This format is designed primarily for fast encoding and decoding, however, the size of the encoded data on the wire was also a consideration.
The OPC UA Binary DataEncoding relies on several primitive data types with clearly defined encoding rules that can be sequentially written to or read from a binary stream. A structure is encoded by sequentially writing the encoded form of each field. If a given field is also a structure, then the values of its fields are written sequentially before writing the next field in the containing structure. All fields shall be written to the stream even if they contain null values. The encodings for each primitive type specify how to encode either a null or a DefaultValue for the type.
The OPC UA Binary DataEncoding does not include any type or field name information because all OPC UA applications are expected to have advance knowledge of the services and structures that they support. An exception is an ExtensionObject which provides an identifier and a size for the Structured DataType structure it represents. This allows a decoder to skip over types that it does not recognize.
5.2.2 Built-in Types
5.2.2.1 Boolean
A Boolean value shall be encoded as a single byte where a value of 0 (zero) is false and any non-zero value is true.
Encoders shall use the value of 1 to indicate a true value; however, decoders shall treat any non-zero value as true.
5.2.2.2 Integer
All integer types shall be encoded as little-endian values where the least significant byte appears first in the stream.
Figure 2 illustrates how value 1 000 000 000 (Hex: 3B9ACA00) is encoded as a 32-bit integer in the stream.
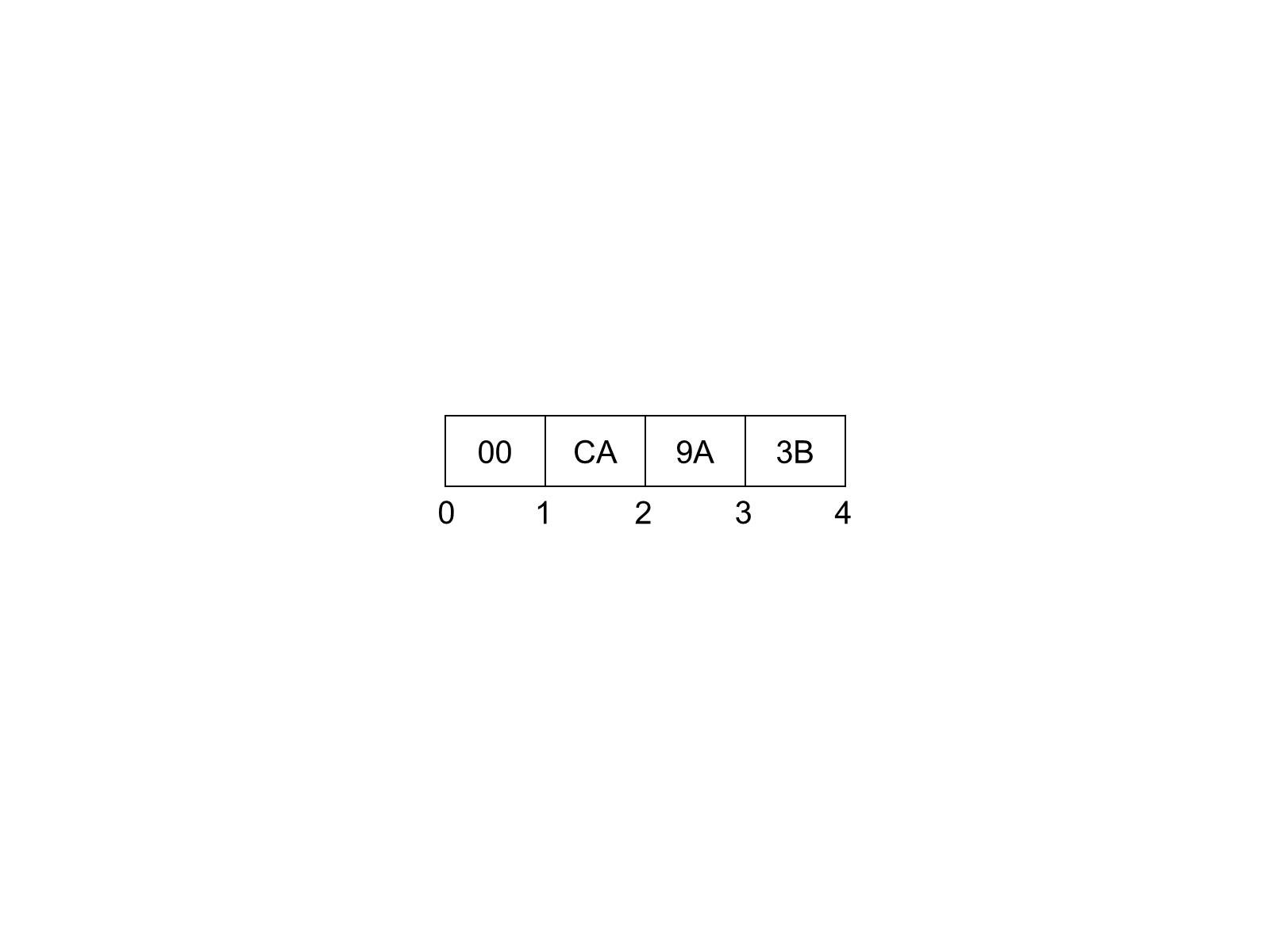
5.2.2.3 Floating-Point
| Name | Width (bits) | Fraction | Exponent | Sign |
|---|---|---|---|---|
| Float | 32 | 0-22 | 23-30 | 31 |
| Double | 64 | 0-51 | 52-62 | 63 |
In addition, the order of bytes in the stream is significant. All floating-point values shall be encoded with the least significant byte appearing first (i.e., little endian).
Figure 3 illustrates how the value -6.5 (Hex: C0D00000) is encoded as a Float.
The floating-point type supports positive and negative infinity and not-a-number (NaN). The IEEE specification allows for multiple NaN variants; however, some encoders/decoders are not able to preserve the distinction. Encoders shall encode a NaN value as an IEEE quiet-NAN (Hex: 000000000000F8FF) or (Hex: 0000C0FF). Any unsupported types such as denormalized numbers shall also be encoded as an IEEE quiet-NAN. Any test for equality between NaN values always fails.
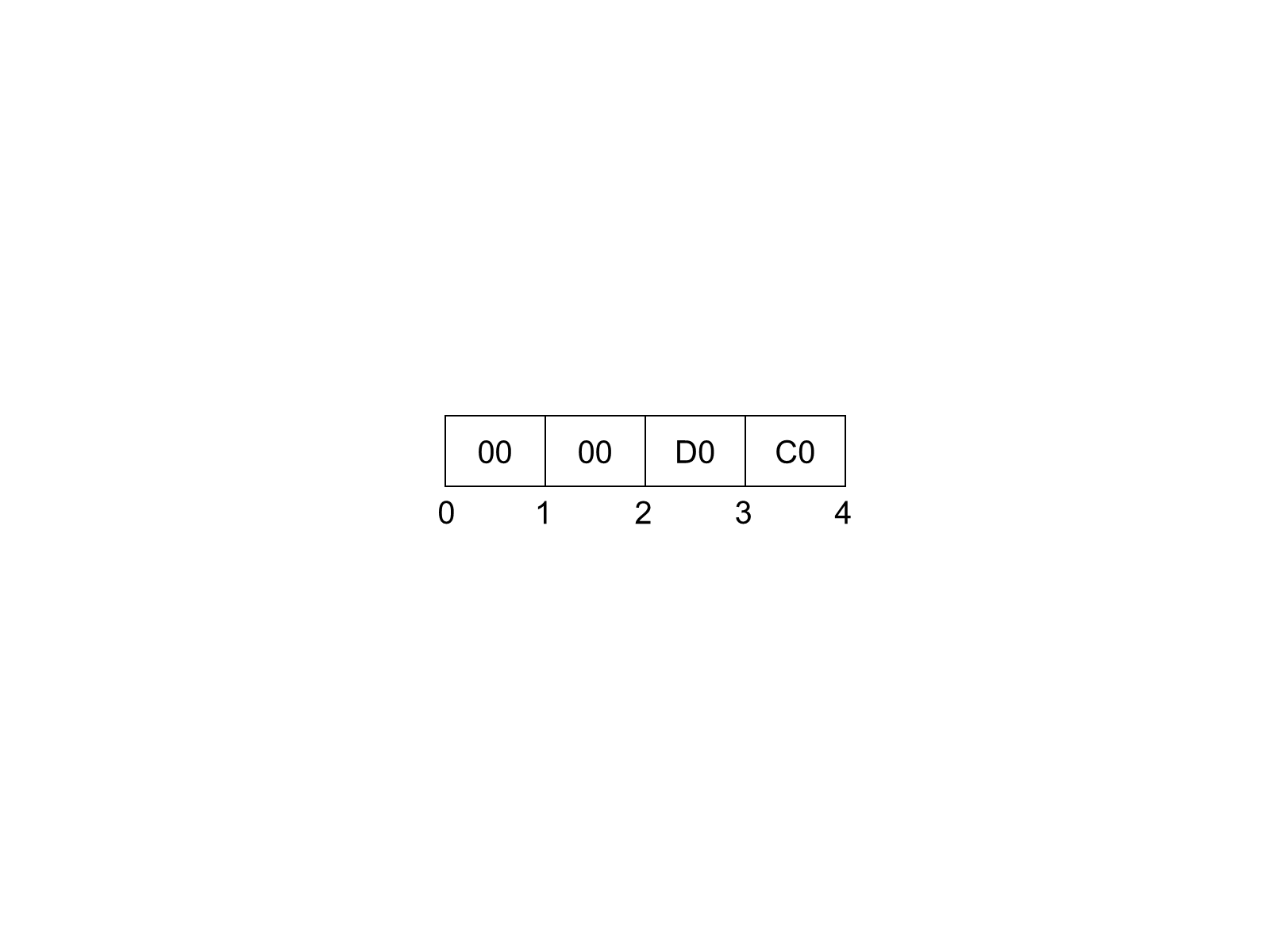
5.2.2.4 String
All String values are encoded as a sequence of UTF-8 characters preceded by the length in bytes.
The length in bytes is encoded as Int32. A value of -1 is used to indicate a 'null' string.
Strings with embedded nulls (U+0000) can lead to unpredictable application behaviour because embedded nulls have special meaning to some DevelopmentPlatforms. For this reason, embedded nulls are not recommended and ByteString should be used instead. That said, Encoders can encode Strings with embedded nulls. Decoders shall use the length to read all bytes in String.
Figure 4 illustrates how the multilingual string '水Boy' is encoded in a byte stream.
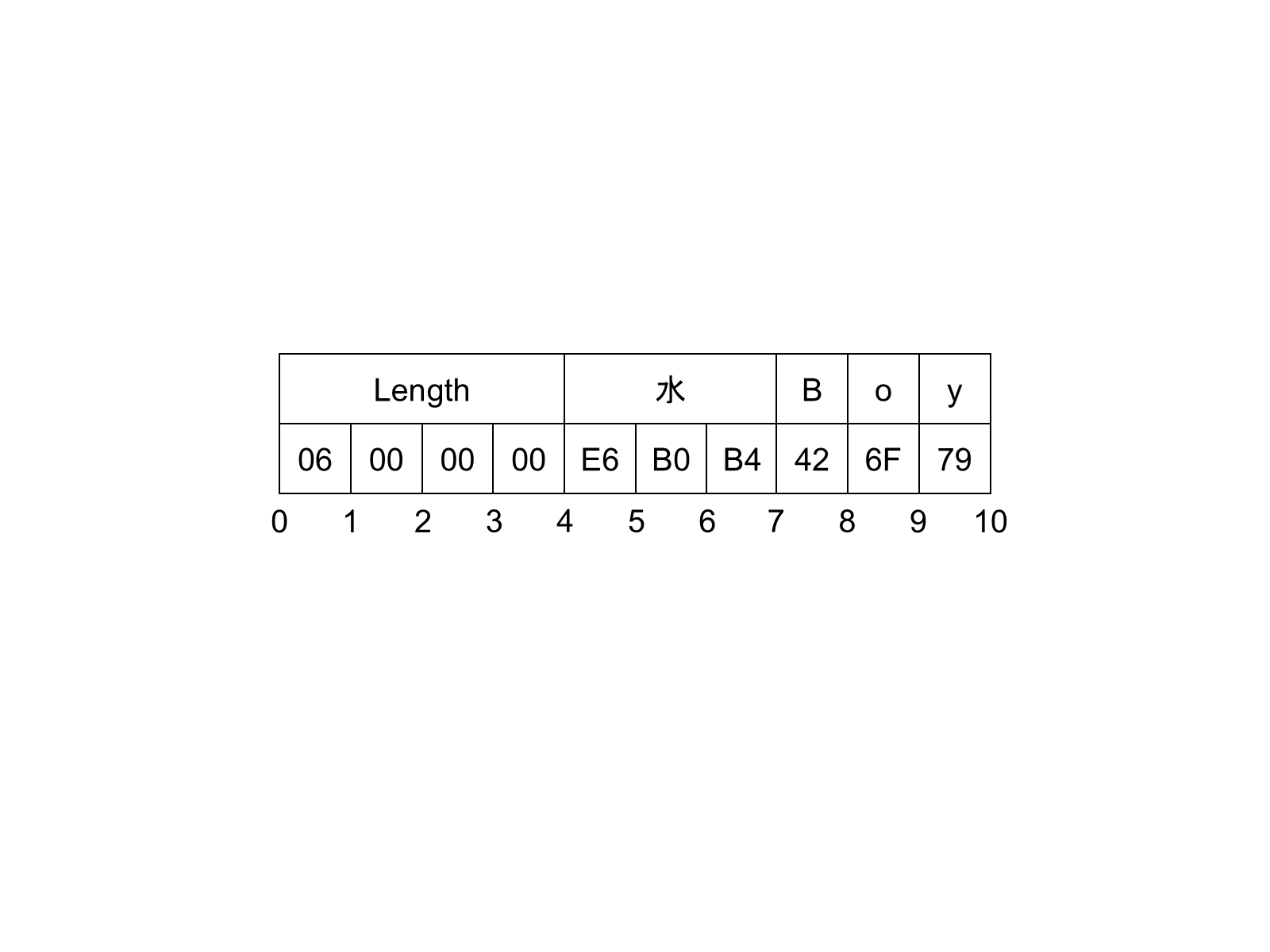
5.2.2.5 DateTime
A DateTime value shall be encoded as a 64-bit signed integer (see 5.2.2.2) which represents the number of 100 nanosecond intervals since January 1, 1601 (UTC).
Not all DevelopmentPlatforms will be able to represent the full range of dates and times that can be represented with this DataEncoding. For example, the UNIX time_t structure only has a 1 second resolution and cannot represent dates prior to 1970. For this reason, a number of rules shall be applied when dealing with date/time values that exceed the dynamic range of a DevelopmentPlatform. These rules are:
A date/time value is encoded as 0 if either:
The value is equal to or earlier than 1601-01-01 12:00AM UTC.
The value is the earliest date that can be represented with the DevelopmentPlatform's encoding.
A date/time is encoded as the maximum value for an Int64 if either:
The value is equal to or greater than 9999-12-31 11:59:59PM UTC,
The value is the latest date that can be represented with the DevelopmentPlatform's encoding.
A date/time is decoded as the earliest time that can be represented on the platform if either:
The encoded value is 0,
The encoded value represents a time earlier than the earliest time that can be represented with the DevelopmentPlatform's encoding.
A date/time is decoded as the latest time that can be represented on the platform if either:
The encoded value is the maximum value for an Int64,
The encoded value represents a time later than the latest time that can be represented with the DevelopmentPlatform's encoding.
These rules imply that the earliest and latest times that can be represented on a given platform are invalid date/time values and should be treated that way by applications.
A decoder shall truncate the value if a decoder encounters a DateTime value with a resolution that is greater than the resolution supported on the DevelopmentPlatform.
5.2.2.6 Guid
A Guid is encoded in a structure as shown in Table 2. Fields are encoded sequentially according to the data type for field.
Figure 5 illustrates how the Guid "72962B91-FA75-4AE6-8D28-B404DC7DAF63" is encoded in a byte stream.
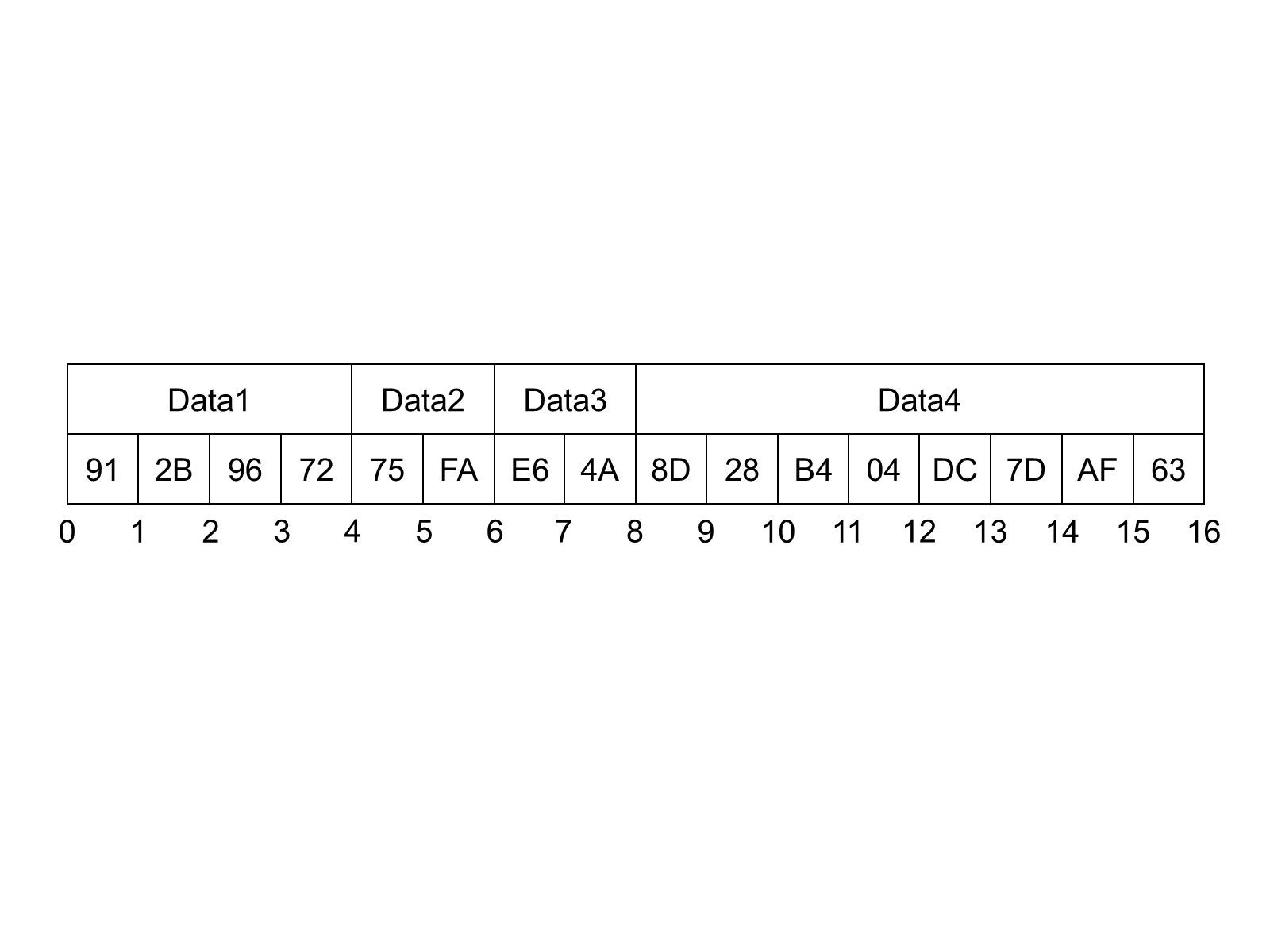
5.2.2.7 ByteString
A ByteString is encoded as sequence of bytes preceded by its length in bytes. The length is encoded as a 32-bit signed integer as described above.
If the length of the byte string is -1 then the byte string is 'null'.
5.2.2.8 XmlElement (Deprecated)
An XmlElement is an XML element serialized as UTF-8 string and then encoded as ByteString.
Figure 6 illustrates how the XmlElement "<A>Hot水</A>" is encoded in a byte stream.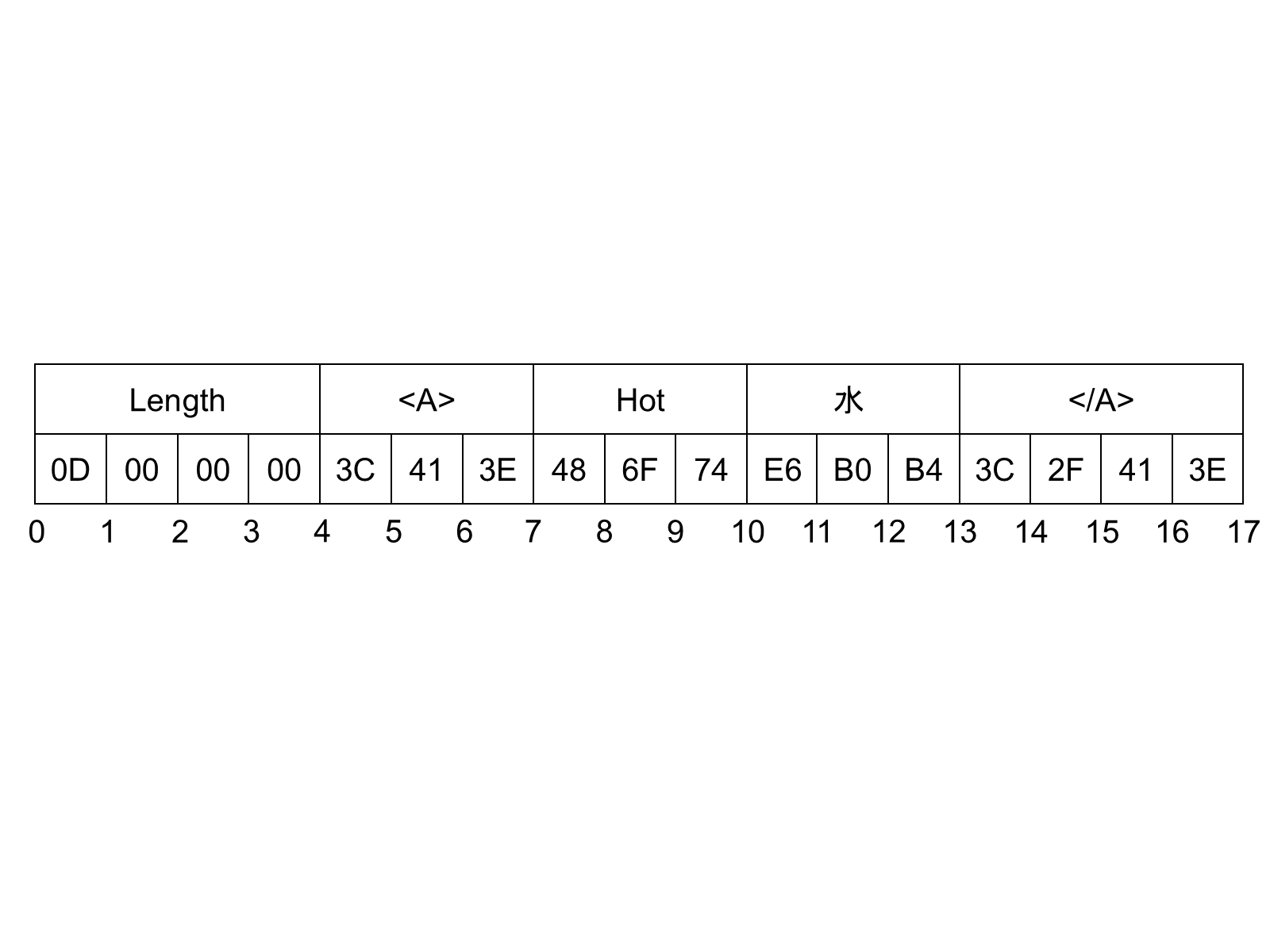
A decoder may choose to parse the XML after decoding; if an unrecoverable parsing error occurs then the decoder should try to continue processing the stream. For example, if the XmlElement is the body of a Variant or an element in an array which is the body of a Variant then this error can be reported by setting value of the Variant to the StatusCode Bad_DecodingError.
5.2.2.9 NodeId
The components of a NodeId are described the Table 16.
| Name | Data Type | Description |
|---|---|---|
| Namespace | UInt16 | The index for a namespace URI. An index of 0 is used for OPC UA defined NodeIds. |
| IdentifierType | Enumeration | The format and data type of the identifier. The value may be one of the following: NUMERIC - the value is an UInt32; STRING - the value is String; GUID - the value is a Guid; OPAQUE - the value is a ByteString; |
| Value | UInt32 or String or Guid or ByteString | The identifier for a node in the address space of an OPC UA Server. |
The DataEncoding of a NodeId varies according to the contents of the instance. For that reason, the first byte of the encoded form indicates the format of the rest of the encoded NodeId. The possible DataEncoding formats are shown in Table 17. Table 17 through Table 20 describe the structure of each possible format (they exclude the byte which indicates the format).
| Name | Value | Description |
|---|---|---|
| Two Byte | 0x00 | A numeric value that fits into the two-byte representation. |
| Four Byte | 0x01 | A numeric value that fits into the four-byte representation. |
| Numeric | 0x02 | A numeric value that does not fit into the two or four byte representations. |
| String | 0x03 | A String value. |
| Guid | 0x04 | A Guid value. |
| ByteString | 0x05 | An opaque (ByteString) value. |
| NamespaceUri Flag | 0x80 | See discussion of ExpandedNodeId in 5.2.2.10. |
| ServerIndex Flag | 0x40 | See discussion of ExpandedNodeId in 5.2.2.10. |
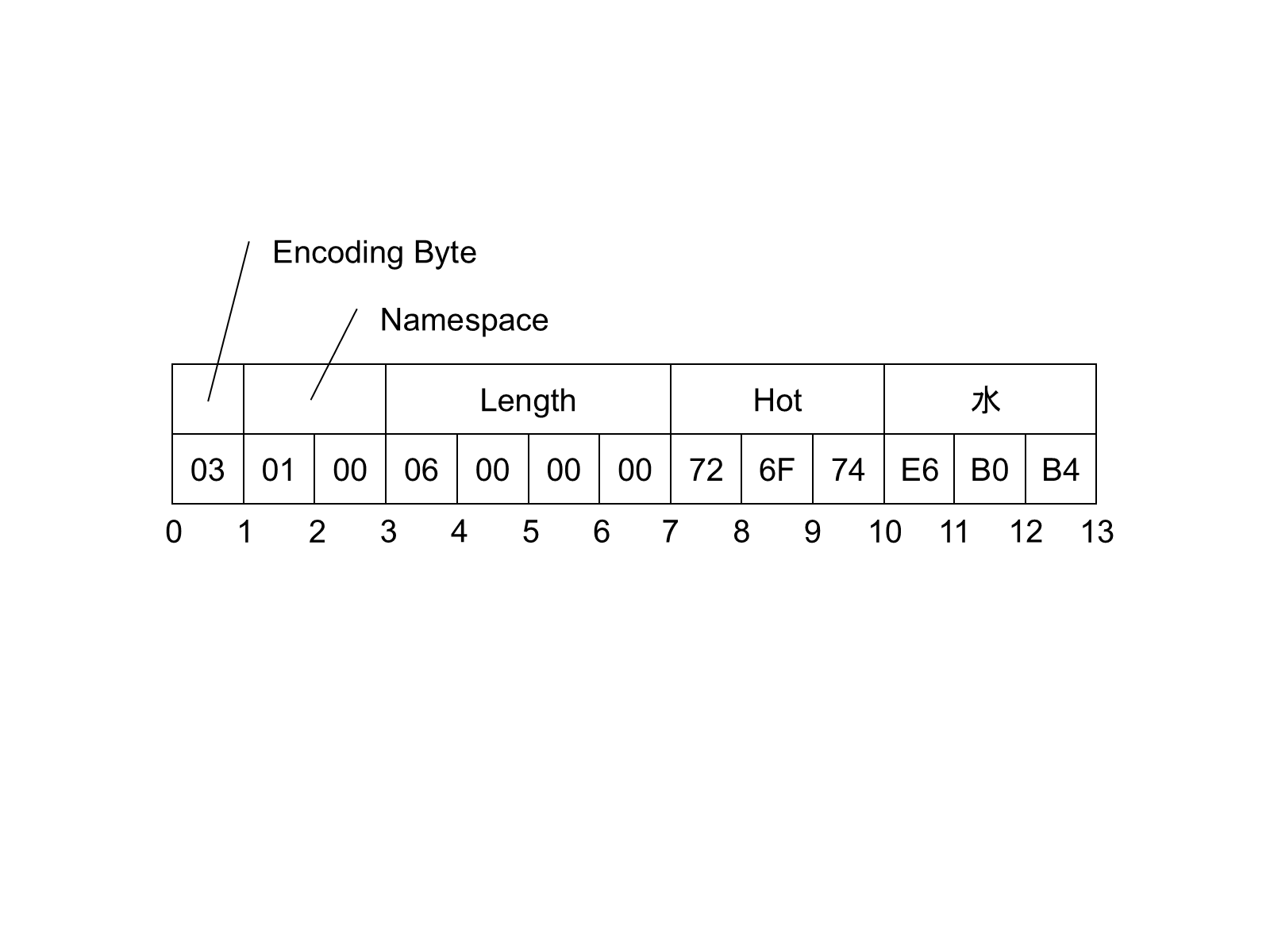
The standard NodeId DataEncoding has the structure shown in Table 18. The standard DataEncoding is used for all formats that do not have an explicit format defined.
| Name | Data Type | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Namespace | UInt16 | The NamespaceIndex. | ||||||||
| Identifier | * | The identifier which is encoded according to the following rules:
|
An example of a String NodeId with Namespace = 1 and Identifier = "Hot水" is shown in Figure 7.
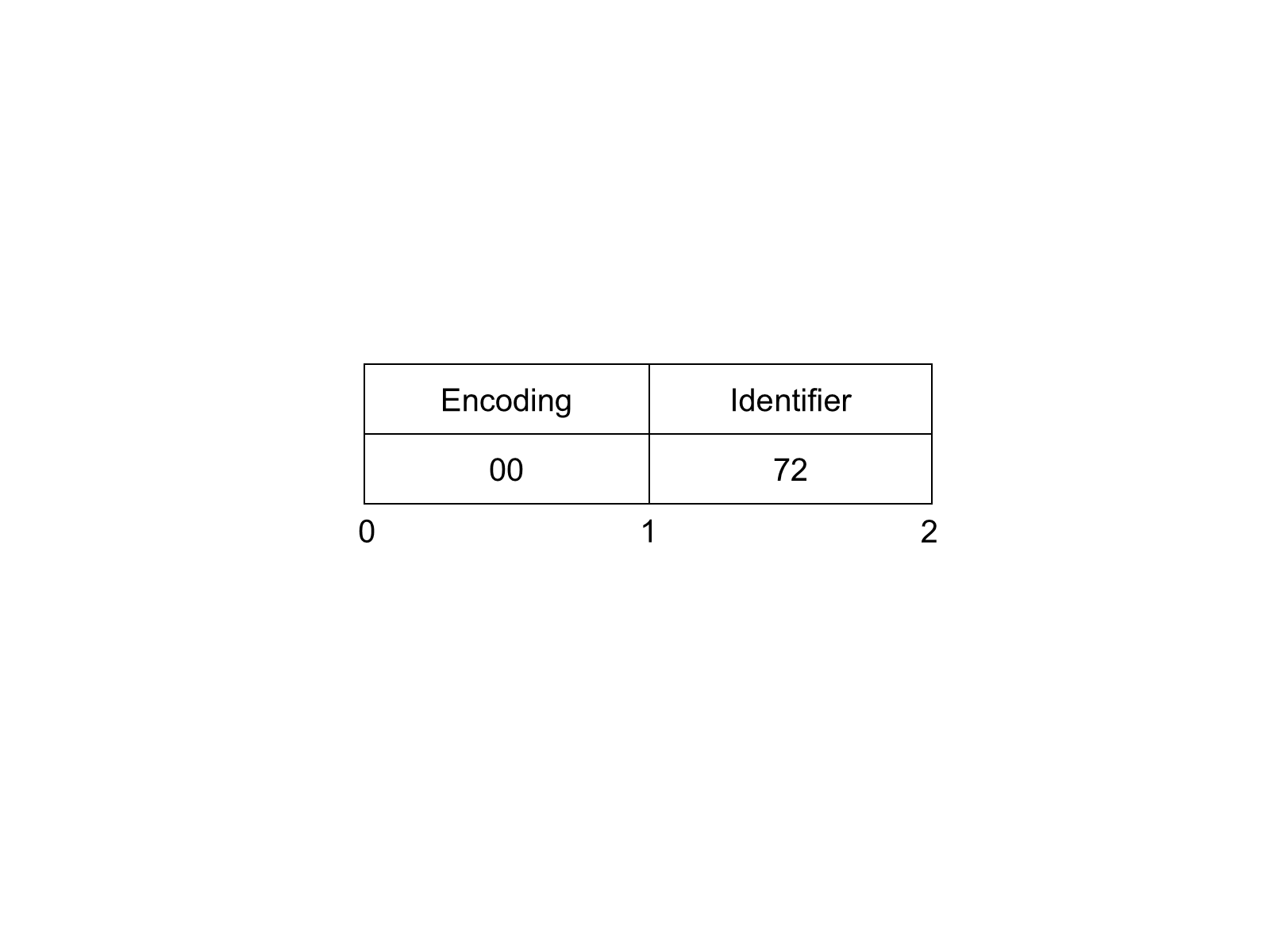
The Two Byte NodeId DataEncoding has the structure shown in Table 19.
| Name | Data Type | Description |
|---|---|---|
| Identifier | Byte | The Namespace is the default OPC UA namespace (i.e. 0). The Identifier Type is 'Numeric'. The Identifier shall be in the range 0 to 255. |
An example of a Two Byte NodeId with Identifier = 72 is shown in Figure 8.
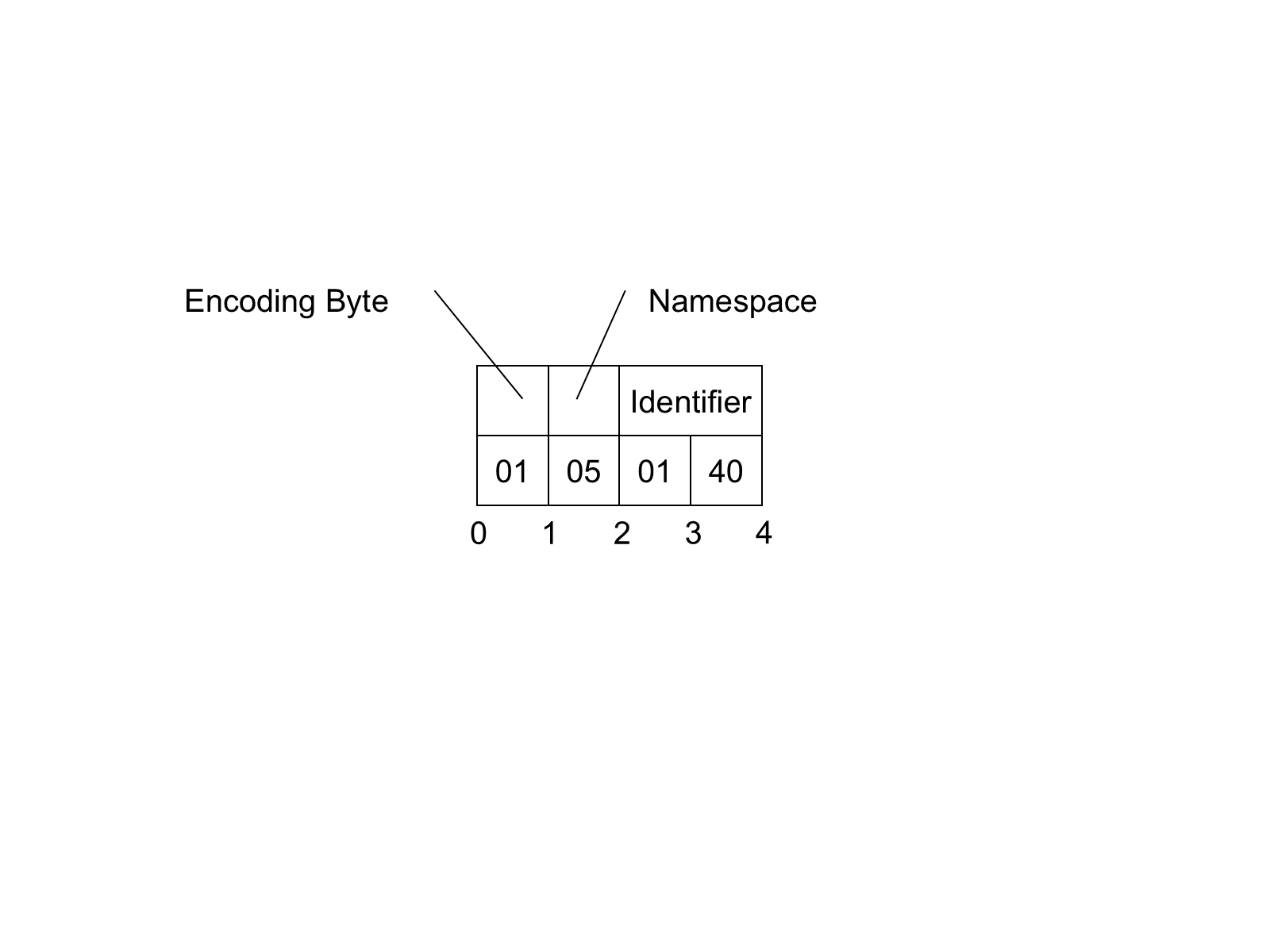
The Four Byte NodeId DataEncoding has the structure shown in Table 20.
| Name | Data Type | Description |
|---|---|---|
| Namespace | Byte | The Namespace shall be in the range 0 to 255. |
| Identifier | UInt16 | The Identifier Type is 'Numeric'. The Identifier shall be an integer in the range 0 to 65 535. |
An example of a Four Byte NodeId with Namespace = 5 and Identifier = 1025 is shown in Figure 9.
5.2.2.10 ExpandedNodeId
An ExpandedNodeId extends the NodeId structure by allowing the NamespaceUri to be explicitly specified instead of using the NamespaceIndex. The NamespaceUri is optional. If it is specified, then the NamespaceIndex inside the NodeId shall be ignored.
The ExpandedNodeId is encoded by first encoding a NodeId as described in 5.2.2.9 and then encoding NamespaceUri as a String.
An instance of an ExpandedNodeId may still use the NamespaceIndex instead of the NamespaceUri. In this case, the NamespaceUri is not encoded in the stream. The presence of the NamespaceUri in the stream is indicated by setting the NamespaceUri flag in the encoding format byte for the NodeId.
If the NamespaceUri is present, then the encoder shall encode the NamespaceIndex as 0 in the stream when the NodeId portion is encoded. The unused NamespaceIndex is included in the stream for consistency.
An ExpandedNodeId may also have a ServerIndex which is encoded as a UInt32 after the NamespaceUri. The ServerIndex flag in the NodeId encoding byte indicates whether the ServerIndex is present in the stream. The ServerIndex is omitted if it is equal to zero.
The ExpandedNodeId encoding has the structure shown in Table 21.
| Name | Data Type | Description |
|---|---|---|
| NodeId | NodeId | The NamespaceUri and ServerIndex flags in the NodeId encoding indicate whether those fields are present in the stream. |
| NamespaceUri | String | Not present if null or empty. |
| ServerIndex | UInt32 | Not present if 0. |
5.2.2.11 StatusCode
A StatusCode is encoded as a UInt32.
5.2.2.12 DiagnosticInfo
A DiagnosticInfo structure is described in OPC 10000-4. It specifies a number of fields that could be missing. For that reason, the encoding uses a bit mask to indicate which fields are actually present in the encoded form.
As described in OPC 10000-4, the SymbolicId, NamespaceUri, LocalizedText and Locale fields are indexes in a string table which is returned in the response header. Only the index of the corresponding string in the string table is encoded. An index of -1 indicates that there is no value for the string.
DiagnosticInfo is recursive and unlimited recursion could result in stack overflow errors even if the message size is less than the maximum allowed. Decoders shall support at least 4 recursion levels and are not expected to support more than 10. Decoders shall report an error if the number of recursion levels exceeds what it supports.
| Name | Data Type | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Encoding Mask | Byte | A bit mask that indicates which fields are present in the stream. The mask has the following bits:
| ||||||||||||||
| SymbolicId | Int32 | A symbolic name for the status code. | ||||||||||||||
| NamespaceUri | Int32 | A namespace that qualifies the symbolic id. | ||||||||||||||
| Locale | Int32 | The locale used for the localized text. | ||||||||||||||
| LocalizedText | Int32 | A human readable summary of the status code. | ||||||||||||||
| Additional Info | String | Detailed application specific diagnostic information. | ||||||||||||||
| Inner StatusCode | StatusCode | A status code provided by an underlying system. | ||||||||||||||
| Inner DiagnosticInfo | DiagnosticInfo | Diagnostic info associated with the inner status code. |
5.2.2.13 QualifiedName
A QualifiedName structure is encoded as shown in Table 23.
The abstract QualifiedName structure is defined in OPC 10000-3.
| Name | Data Type | Description |
|---|---|---|
| NamespaceIndex | UInt16 | The namespace index. |
| Name | String | The name. |
5.2.2.14 LocalizedText
A LocalizedText structure contains two fields that could be missing. For that reason, the encoding uses a bit mask to indicate which fields are actually present in the encoded form.
The abstract LocalizedText structure is defined in OPC 10000-3.
| Name | Data Type | Description | ||||
|---|---|---|---|---|---|---|
| EncodingMask | Byte | A bit mask that indicates which fields are present in the stream. The mask has the following bits:
| ||||
| Locale | String | The locale. Omitted is null or empty. | ||||
| Text | String | The text in the specified locale. Omitted is null or empty. |
5.2.2.15 ExtensionObject
An ExtensionObject is encoded as sequence of bytes prefixed by the NodeId of its DataTypeEncoding, the DataEncoding used and the number of bytes encoded.
An ExtensionObject may be serialized as a ByteString or an XmlElement by the application and then passed to the encoder. In this case, the encoder will be able to write the number of bytes in the object before it encodes the bytes. However, an ExtensionObject knows how to encode/decode itself which means the encoder shall calculate the number of bytes before it encodes the object or it shall be able to seek backwards in the stream and update the length after encoding the body.
When a decoder encounters an ExtensionObject it shall check if it recognizes the DataTypeEncoding identifier. If it does, then it can call the appropriate function to decode the object body. If the decoder does not recognize the type, it shall use the Encoding to determine if the body is a ByteString or an XmlElement and then decode the object body or treat it as opaque data and skip over it.
If the Encoding is Binary the Body uses the OPC UA Binary DataEncoding. If the Encoding is XML the Body uses the OPC UA XML DataEncoding. Other DataEncodings may not be serialized in an ExtensionObject.
The serialized form of an ExtensionObject is shown in Table 25.
| Name | Data Type | Description | ||||||
|---|---|---|---|---|---|---|---|---|
| TypeId | NodeId | The identifier for the DataTypeEncoding node in the Server's AddressSpace. ExtensionObjects defined by the OPC UA specification have a numeric node identifier assigned to them with a NamespaceIndex of 0. The numeric identifiers are defined in A.3. Decoders use this field to determine the syntax of the Body. | ||||||
| Encoding | Byte | An enumeration that indicates how the body is encoded. The parameter may have the following values:
| ||||||
| Length | Int32 | The length of the object body. The length shall be specified if the body is encoded. | ||||||
| Body | OctetString | The object encoded with the DataEncoding indicated by the TypeId. This field contains the raw bytes for ByteString bodies. For XmlElement bodies this field contains the XML encoded as a UTF-8 string without any null terminator. |
A decoder may choose to parse an XmlElement body after decoding; if an unrecoverable parsing error occurs then the decoder should try to continue processing the stream. For example, if the ExtensionObject is the body of a Variant or an element in an array that is the body of Variant then this error can be reported by setting the value of the Variant to the StatusCode Bad_DecodingError.
A null value for an ExtensionObject is encoded with a TypeId set to 'i=0' and the Encoding set to 0.
5.2.2.16 Variant
A Variant is a union of the built-in types.
The structure of a Variant is shown in Table 26.
| Name | Data Type | Description | ||||||
|---|---|---|---|---|---|---|---|---|
| EncodingMask | Byte | The type of data encoded in the stream.
The built-in Type Ids 26 through 31 are not currently assigned but may be used in the future. Decoders shall accept these IDs, assume the Value contains a ByteString or an array of ByteStrings and pass both onto the application. Encoders shall not use these IDs. The ArrayDimensions field shall only be present if the number of dimensions is 2 or greater and all dimensions have a length greater than 0. | ||||||
| ArrayLength | Int32 | The number of elements in the array. This field is only present if the array bit is set in the encoding mask. Multi-dimensional arrays are encoded as a one-dimensional array and this field specifies the total number of elements. The original array can be reconstructed from the dimensions that are encoded after the value field. Higher rank dimensions are serialized first. For example, an array with dimensions [2,2,2] is written in this order: [0,0,0], [0,0,1], [0,1,0], [0,1,1], [1,0,0], [1,0,1], [1,1,0], [1,1,1] If one or more dimensions has a length <= 0 then the ArrayLength is 0. | ||||||
| Value | * | The value encoded according to its built-in data type. If the array bit is set in the encoding mask, then each element in the array is encoded sequentially. Since many types have variable length encoding each element shall be decoded in order. The value shall not be a Variant but it could be an array of Variants. Many implementation platforms do not distinguish between one dimensional Arrays of Bytes and ByteStrings. For this reason, decoders are allowed to automatically convert an Array of Bytes to a ByteString. | ||||||
| ArrayDimensions Length | Int32 | The number of dimensions. This field is only present if the ArrayDimensions flag is set in the encoding mask. | ||||||
| ArrayDimensions | Int32[] | The length of each dimension encoded as a sequence of Int32 values This field is only present if the ArrayDimensions flag is set in the encoding mask. The lower rank dimensions appear first in the array. All dimensions shall be specified and shall be greater than zero.. If ArrayDimensions are inconsistent with the ArrayLength then the decoder shall stop and raise a Bad_DecodingError. |
The types and their identifiers that can be encoded in a Variant are shown in Table 1.
5.2.2.17 DataValue
A DataValue is always preceded by a mask that indicates which fields are present in the stream.
The fields of a DataValue are described in Table 27.
| Name | Data Type | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Encoding Mask | Byte | A bit mask that indicates which fields are present in the stream. The mask has the following bits:
| ||||||||||||
| Value | Variant | The value. Not present if the Value bit in the EncodingMask is False. | ||||||||||||
| Status | StatusCode | The status associated with the value. Not present if the StatusCode bit in the EncodingMask is False. | ||||||||||||
| SourceTimestamp | DateTime | The source timestamp associated with the value. Not present if the SourceTimestamp bit in the EncodingMask is False. | ||||||||||||
| SourcePicoseconds | UInt16 | The number of 10 Picosecond intervals for the SourceTimestamp. Not present if the SourcePicoseconds bit in the EncodingMask is False. If the source timestamp is missing the Picoseconds are ignored. | ||||||||||||
| ServerTimestamp | DateTime | The Server timestamp associated with the value. Not present if the ServerTimestamp bit in the EncodingMask is False. | ||||||||||||
| ServerPicoseconds | UInt16 | The number of 10 Picosecond intervals for the ServerTimestamp. Not present if the ServerPicoseconds bit in the EncodingMask is False. If the Server timestamp is missing the Picoseconds are ignored. |
The Picoseconds fields store the difference between a high-resolution timestamp with a resolution of 10 Picoseconds and the Timestamp field value which only has a 100 ns resolution. The Picoseconds fields shall contain values less than 10 000. The decoder shall treat values greater than or equal to 10 000 as the value '9999'.
5.2.3 Decimal
Decimals are encoded as described in 5.1.10.
A Decimal does not have a NULL value.
5.2.4 Enumerations
Enumerations are encoded as Int32 values.
An Enumeration does not have a NULL value.
5.2.5 Arrays
One dimensional Arrays are encoded as a sequence of elements preceded by the number of elements encoded as an Int32 value.
Multi-dimensional Arrays have an encoding that depends on where they are used. When a multi-dimensional Array is the Value of an Attribute it uses the Variant encoding described in 5.2.2.16.
When a multi-dimensional Array is a field of a Structure (see 5.2.6) it shall be encoded with the inline matrix representation as shown in Table 28.
| Name | Data Type | Description |
|---|---|---|
| Dimensions | Int32 [] | The length of each dimension. If any dimension has a length <= 0, then no values are encoded. The number of dimensions shall be at least 2. |
| Values | * | The values encoded sequentially according to its built-in data type. The total number of values is the product of the dimensions. The mapping of a multidimensional array to a flat list is described in 5.2.2.16. |
The inline matrix representation is not supported by earlier versions of this specification. This means any Structure with a field or nested field mapped to an inline matrix is not compatible with the deprecated DataTypeDictionary mechanism, and shall not be included in a DataTypeDictionary.
If an Array is null, then its length is encoded as -1. See 5.1.11 for a discussion of zero-length vs null arrays.
5.2.6 Structures
Structures are encoded as a sequence of fields in the order that they appear in the definition. The encoding for each field is determined by the built-in type for the field.
All fields specified in the structure shall be encoded. If optional fields exist in the Structure, then see 5.2.7.
Structures do not have a null value. If an encoder is written in a programming language that allows structures to have null values, then the encoder shall create a new instance with DefaultValues for all fields and serialize that. Encoders shall not generate an encoding error in this situation.
The following is an example of a structure using C/C++ syntax:
struct Type2
{
Int32 A;
Int32 B;
};
struct Type1
{
Int32 X;
Byte NoOfY;
Type2* Y;
Int32 Z;
UInt16 W[10];
Byte M[2,3,4];
};
In the C/C++ example above, the Y field is a pointer to an array with a length stored in NoOfY. When encoding an array, the length is part of the array encoding so the NoOfY field is not encoded. That said, encoders and decoders use NoOfY during encoding. W is a fixed length array with an implicitly defined length of 10. This length is always encoded with the array. M is a fixed length multidimensional array. The length of each dimension is always encoded with the array.
An instance of Type1 which contains an array of two Type2 instances would be encoded as 28-byte sequence. If the instance of Type1 was encoded in an ExtensionObject it would have an additional prefix shown in Table 29 which would make the total length 101 bytes. The TypeId, Encoding and the Length are fields defined by the ExtensionObject. The encoding of the Type2 instances do not include any type identifier because it is explicitly defined in Type1.
| Field | Bytes | Value |
|---|---|---|
| Type Id | 4 | The identifier for the 'Type1' Binary Encoding Node |
| Encoding | 1 | 0x1 for ByteString |
| Length | 4 | 92 |
| X | 4 | The value of field 'X' |
| Y.Length | 4 | 2 |
| Y.A | 4 | The value of field 'Y[0].A' |
| Y.B | 4 | The value of field 'Y[0].B' |
| Y.A | 4 | The value of field 'Y[1].A' |
| Y.B | 4 | The value of field 'Y[1].B' |
| Z | 4 | The value of field 'Z' |
| W.Length | 4 | 10 |
| W | 20 | The value of field 'W'. |
| M.Dimensions.Length | 4 | 3 |
| M.Dimensions | 12 | The sequence [2,3,4] encoded as a Int32. |
| M.Values | 24 | The values in 'M' encoded sequentially as described in 5.2.2.16. |
The Value of the DataTypeDefinition Attribute for a DataType Node describing Type1 is shown in Table 30.
| Name | Type | Description |
| defaultEncodingId | NodeId | NodeId of the "Type1_Encoding_DefaultBinary" Node. |
| baseDataType | NodeId | "i=22" [Structure] |
| structureType | StructureType | Structure_0 [Structure without optional fields] |
| fields [0] | StructureField | |
name | String | "X" |
description | LocalizedText | Description of X |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [1] | StructureField | |
name | String | "Y" |
description | LocalizedText | Description of Y-Array |
dataType | NodeId | NodeId of the Type2 DataType Node (e.g. "ns=3;s=MyType2") |
valueRank | Int32 | 1 (OneDimension) |
arrayDimensions | UInt32[] | { 0 } |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [2] | StructureField | |
name | String | "Z" |
description | LocalizedText | Description of Z |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [3] | StructureField | |
name | String | "W" |
description | LocalizedText | Description of W |
dataType | NodeId | "i=5" [UInt16] |
valueRank | Int32 | 1 (OneDimension) |
arrayDimensions | UInt32[] | { 10 } |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [4] | StructureField | |
name | String | "M" |
description | LocalizedText | Description of M |
dataType | NodeId | "i=3" [Byte] |
valueRank | Int32 | 3 |
arrayDimensions | UInt32[] | { 2, 3, 4 } |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
The Value of the DataTypeDefinition Attribute for a DataType Node describing Type2 is shown in Table 31.
| Name | Type | Description |
| defaultEncodingId | NodeId | NodeId of the "Type2_Encoding_DefaultBinary" Node. |
| baseDataType | NodeId | "i=22" [Structure] |
| structureType | StructureType | Structure_0 [Structure without optional fields] |
| fields [0] | StructureField | |
name | String | "A" |
description | LocalizedText | Description of A |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [1] | StructureField | |
name | String | "B" |
description | LocalizedText | Description of B |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
5.2.7 Structures with optional fields
Structures with optional fields are encoded with an encoding mask preceding a sequence of fields in the order that they appear in the definition. The encoding for each field is determined by the data type for the field.
The EncodingMask is a 32-bit unsigned integer. Each optional field is assigned exactly one bit. The first optional field is assigned bit '0', the second optional field is assigned bit '1' and so until all optional fields are assigned bits. A maximum of 32 optional fields can appear within a single Structure. Unassigned bits are set to 0 by encoders. Decoders shall report an error if unassigned bits are not 0.
The following is an example of a structure with optional fields using C++ syntax:
struct TypeA
{
Int32 X;
Int32* O1;
SByte Y;
Int32* O2;
};
O1 and O2 are optional fields which are NULL if not present
An instance of TypeA which contains two mandatory (X and Y) and two optional (O1 and O2) fields would be encoded as a byte sequence. The length of the byte sequence depends on the available optional fields. An encoding mask field determines the available optional fields.
An instance of TypeA where field O2 is available and field O1 is not available would be encoded as a 13-byte sequence. If the instance of TypeA was encoded in an ExtensionObject it would have the encoded form shown in Table 32 and have a total length of 22 bytes. The length of the TypeId, Encoding and the Length are fields defined by the ExtensionObject.
| Field | Bytes | Value |
|---|---|---|
| Type Id | 4 | The identifier for the TypeA Binary Encoding Node |
| Encoding | 1 | 0x1 for ByteString |
| Length | 4 | 13 |
| EncodingMask | 4 | 0x02 for O2 |
| X | 4 | The value of X |
| Y | 1 | The value of Y |
| O2 | 4 | The value of O2 |
If a Structure with optional fields is subtyped, the subtypes extend the EncodingMask defined for the parent.
The Value of the DataTypeDefinition Attribute for a DataType Node describing TypeA is:
| Name | Type | Description |
| defaultEncodingId | NodeId | NodeId of the "TypeA_Encoding_DefaultBinary" Node. |
| baseDataType | NodeId | "i=22" [Structure] |
| structureType | StructureType | StructureWithOptionalFields_1 [Structure without optional fields] |
| fields [0] | StructureField | |
name | String | "X" |
description | LocalizedText | Description of X |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [1] | StructureField | |
name | String | "O1" |
description | LocalizedText | Description of O1 |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | true |
| fields [2] | StructureField | |
name | String | "Y" |
description | LocalizedText | Description of Z |
dataType | NodeId | "i=2" [SByte] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [3] | StructureField | |
name | String | "O2" |
description | LocalizedText | Description of O2 |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | true |
5.2.8 Unions
Unions are encoded as a switch field preceding one of the possible fields. The encoding for the selected field is determined by the data type for the field.
The switch field is encoded as a UInt32.
The switch field is the index of the available union fields starting with 1. If the switch field is 0 then no field is present. For any value greater than the number of defined union fields the encoders or decoders shall report an error.
A Union with no fields present has the same meaning as a NULL value. A Union with any field present is not a NULL value even if the value of the field itself is NULL.
The following is an example of a union using C/C++ syntax:
struct Type2
{
Int32 A;
Int32 B;
};
struct Type1
{
Byte Selector;
union
{
Int32 Field1;
Type2 Field2;
}
Value;
};
In the C/C++ example above, the Selector, Field1 and Field2 are semantically coupled to form a union.
An instance of Type1 would be encoded as byte sequence. The length of the byte sequence depends on the selected field.
An instance of Type1 where field Field1 is available would be encoded as 8-byte sequence. If the instance of Type 1 was encoded in an ExtensionObject it would have the encoded form shown in Table 33 and it would have a total length of 17 bytes. The TypeId, Encoding and the Length are fields defined by the ExtensionObject.
| Field | Bytes | Value |
|---|---|---|
| Type Id | 4 | The identifier for Type1 |
| Encoding | 1 | 0x1 for ByteString |
| Length | 4 | 8 |
| SwitchValue | 4 | 1 for Field1 |
| Field1 | 4 | The value of Field1 |
The Value of the DataTypeDefinition Attribute for a DataType Node describing Type1 is:
| Name | Type | Description |
| defaultEncodingId | NodeId | NodeId of the "Type1_Encoding_DefaultBinary" Node. |
| baseDataType | NodeId | "i=22" [Union] |
| structureType | StructureType | Union_2 [Union] |
| fields [0] | StructureField | |
name | String | "Field1" |
description | LocalizedText | Description of Field1 |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | true |
| fields [1] | StructureField | |
name | String | "Field2" |
description | LocalizedText | Description of Field2 |
dataType | NodeId | NodeId of the Type2 DataType Node (e.g. "ns=3;s=MyType2") |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | true |
The Value of the DataTypeDefinition Attribute for a DataType Node describing Type2 is:
| Name | Type | Description |
| defaultEncodingId | NodeId | NodeId of the "Type2_Encoding_DefaultBinary" Node. |
| baseDataType | NodeId | "i=22" [Structure] |
| structureType | StructureType | Structure_0 [Structure without optional fields] |
| fields [0] | StructureField | |
name | String | "A" |
description | LocalizedText | Description of A |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
| fields [1] | StructureField | |
name | String | "B" |
description | LocalizedText | Description of B |
dataType | NodeId | "i=6" [Int32] |
valueRank | Int32 | -1 (Scalar) |
arrayDimensions | UInt32[] | null |
maxStringLength | UInt32 | 0 |
isOptional | Boolean | false |
5.2.9 Messages
Messages are Structures encoded as sequence of bytes prefixed by the NodeId of for the OPC UA Binary DataTypeEncoding defined for the Message.
Each OPC UA Service described in OPC 10000-4 has a request and response Message. The DataTypeEncoding IDs assigned to each Service are specified in Clause A.3.
5.3 OPC UA XML
5.3.1 Built-in Types
5.3.1.1 General
5.3.1.2 Boolean
A Boolean value is encoded as an xs:boolean value.
5.3.1.3 Integer
Integer values are encoded using one of the subtypes of the xs:decimal type. The mappings between the OPC UA integer types and XML schema data types are shown in Table 34.
| Name | XML Type |
|---|---|
| SByte | xs:byte |
| Byte | xs:unsignedByte |
| Int16 | xs:short |
| UInt16 | xs:unsignedShort |
| Int32 | xs:int |
| UInt32 | xs:unsignedInt |
| Int64 | xs:long |
| UInt64 | xs:unsignedLong |
5.3.1.4 Floating-Point
Floating-point values are encoded using one of the XML floating-point types. The mappings between the OPC UA floating-point types and XML schema data types are shown in Table 35.
| Name | XML Type |
|---|---|
| Float | xs:float |
| Double | xs:double |
The XML floating-point type supports positive infinity (INF), negative infinity (-INF) and not-a-number (NaN).
5.3.1.5 String
A String value is encoded as an xs:string value.
Strings with embedded nulls (U+0000) are not guaranteed to be interoperable because not all DevelopmentPlatforms can handle Strings with embedded nulls. For this reason, embedded nulls are not recommended. Encoders may encode Strings with embedded nulls. Decoders shall read all bytes in String; however, decoders may truncate the String at the first embedded null before passing it on to the application.
5.3.1.6 DateTime
A DateTime value is encoded as an xs:dateTime value.
All DateTime values shall be encoded as UTC times or with the time zone explicitly specified.
Correct:
2002-10-10T00:00:00+05:00
2002-10-09T19:00:00ZIncorrect:
2002-10-09T19:00:00It is recommended that all xs:dateTime values be represented in UTC format.
The earliest and latest date/time values that can be represented on a DevelopmentPlatform have special meaning and shall not be literally encoded in XML.
The earliest date/time value on a DevelopmentPlatform shall be encoded in XML as '0001-01-01T00:00:00Z'.
The latest date/time value on a DevelopmentPlatform shall be encoded in XML as '9999-12-31T23:59:59Z'
If a decoder encounters a xs:dateTime value that cannot be represented on the DevelopmentPlatform it should convert the value to either the earliest or latest date/time that can be represented on the DevelopmentPlatform. The XML decoder should not generate an error if it encounters an out of range date value.
The earliest date/time value on a DevelopmentPlatform is equivalent to a null date/time value.
5.3.1.7 Guid
A Guid is encoded using the string representation defined in 5.1.3.
The XML schema for a Guid is:
<xs:complexType name="Guid">
<xs:sequence>
<xs:element name="String" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>5.3.1.8 ByteString
A ByteString value is encoded as an xs:base64Binary value (see Base64).
The XML schema for a ByteString is:
<xs:element name="ByteString" type="xs:base64Binary" nillable="true"/>5.3.1.9 XmlElement (Deprecated)
An XmlElement value is encoded as an xs:complexType with the following XML schema:
<xs:complexType name="XmlElement">
<xs:sequence>
<xs:any minOccurs="0" maxOccurs="1" processContents="lax" />
</xs:sequence>
</xs:complexType>XmlElements may only be used inside Variant or ExtensionObject values.
5.3.1.10 NodeId
A NodeId value is encoded as an xs:string with the syntax defined in 5.1.12.
The XML schema for a NodeId is:
<xs:complexType name="NodeId">
<xs:sequence>
<xs:element name="Identifier" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
5.3.1.11 ExpandedNodeId
An ExpandedNodeId value is encoded as an xs:string with the syntax defined in 5.1.12.
The XML schema for an ExpandedNodeId is:
<xs:complexType name="ExpandedNodeId">
<xs:sequence>
<xs:element name="Identifier" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
5.3.1.12 StatusCode
A StatusCode is encoded as an xs:unsignedInt with the following XML schema:
<xs:complexType name="StatusCode">
<xs:sequence>
<xs:element name="Code" type="xs:unsignedInt" minOccurs="0" />
</xs:sequence>
</xs:complexType>
5.3.1.13 DiagnosticInfo
An DiagnosticInfo value is encoded as an xs:complexType with the following XML schema:
<xs:complexType name="DiagnosticInfo">
<xs:sequence>
<xs:element name="SymbolicId" type="xs:int" minOccurs="0" />
<xs:element name="NamespaceUri" type="xs:int" minOccurs="0" />
<xs:element name="Locale" type="xs:int" minOccurs="0/>
<xs:element name="LocalizedText" type="xs:int" minOccurs="0/>
<xs:element name="AdditionalInfo" type="xs:string" minOccurs="0"/>
<xs:element name="InnerStatusCode" type="tns:StatusCode"
minOccurs="0" />
<xs:element name="InnerDiagnosticInfo" type="tns:DiagnosticInfo"
minOccurs="0" />
</xs:sequence>
</xs:complexType>
DiagnosticInfo is recursive and unlimited recursion could result in stack overflow errors even if the message size is less than the maximum allowed. Decoders shall support at least 4 recursion levels and are not expected to support more than 10. Decoders shall report an error if the number of recursion levels exceeds what it supports.
5.3.1.14 QualifiedName
A QualifiedName value is encoded as an xs:complexType with the following XML schema:
<xs:complexType name="QualifiedName">
<xs:sequence>
<xs:element name="NamespaceIndex" type="xs:int" minOccurs="0" />
<xs:element name="Name" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>5.3.1.15 LocalizedText
A LocalizedText value is encoded as an xs:complexType with the following XML schema:
<xs:complexType name="LocalizedText">
<xs:sequence>
<xs:element name="Locale" type="xs:string" minOccurs="0" />
<xs:element name="Text" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
5.3.1.16 ExtensionObject
An ExtensionObject value is encoded as an xs:complexType with the following XML schema:
<xs:complexType name="ExtensionObject">
<xs:sequence>
<xs:element name="TypeId" type="tns:NodeId" minOccurs="0" />
<xs:element name="Body" minOccurs="0">
<xs:complexType>
<xs:sequence>
<xs:any minOccurs="0" processContents="lax"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
The body of the ExtensionObject contains a single element which is either a ByteString or XML encoded Structure. A decoder can distinguish between the two by inspecting the top-level element. An XML element with the name tns:ByteString contains an OPC UA Binary encoded body. Any other XML element name shall contain an OPC UA XML encoded body. Other DataEncodings may not be serialized in an ExtensionObject.
The TypeId should be the NodeId for the DataTypeEncoding Node. The NodeId of DataType Node may also be used when the body is encoded with the XML encoding.
5.3.1.17 Variant
A Variant value is encoded as an xs:complexType with the following XML schema:
<xs:complexType name="Variant">
<xs:sequence>
<xs:element name="Value" minOccurs="0" nillable="true">
<xs:complexType>
<xs:sequence>
<xs:any minOccurs="0" processContents="lax"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
If the Variant represents a scalar value, then it shall contain a single child element with the name of the built-in type. For example, the single precision floating-point value 3.1415 would be encoded as:
<tns:Float>3.1415</tns:Float>If the Variant represents a single dimensional array, then it shall contain a single child element with the prefix 'ListOf' and the name built-in type. For example, an Array of strings would be encoded as:
<tns:ListOfString>
<tns:String>Hello</tns:String>
<tns:String>World</tns:String>
</tns:ListOfString>If the Variant represents a multidimensional Array, then it shall contain a child element with the name 'Matrix' with the two sub-elements shown in this example:
<tns:Matrix>
<tns:Dimensions>
<tns:Int32>2</tns:Int32>
<tns:Int32>2</tns:Int32>
</tns:Dimensions>
<tns:Elements>
<tns:String>A</tns:String>
<tns:String>B</tns:String>
<tns:String>C</tns:String>
<tns:String>D</tns:String>
</tns:Elements>
</tns:Matrix>
In this example, the array has the following elements:
[0,0] = "A"; [0,1] = "B"; [1,0] = "C"; [1,1] = "D"The elements of a multi-dimensional Array are always flattened into a single dimensional Array where the higher rank dimensions are serialized first. This single dimensional Array is encoded as a child of the 'Elements' element. The 'Dimensions' element is an Array of Int32 values that specify the dimensions of the array starting with the lowest rank dimension. The multi-dimensional Array can be reconstructed by using the dimensions encoded. All dimensions shall be specified and shall be greater than zero. If the dimensions are inconsistent with the number of elements in the array, then the decoder shall stop and raise a Bad_DecodingError.
The complete set of built-in type names is found in Table 1.
5.3.1.18 DataValue
A DataValue value is encoded as a xs:complexType with the following XML schema:
<xs:complexType name="DataValue">
<xs:sequence>
<xs:element name="Value" type="tns:Variant" minOccurs="0"
nillable="true" />
<xs:element name="StatusCode" type="tns:StatusCode"
minOccurs="0" />
<xs:element name="SourceTimestamp" type="xs:dateTime"
minOccurs="0" />
<xs:element name="SourcePicoseconds" type="xs:unsignedShort"
minOccurs="0"/>
<xs:element name="ServerTimestamp" type="xs:dateTime"
minOccurs="0" />
<xs:element name="ServerPicoseconds" type="xs:unsignedShort"
minOccurs="0"/>
</xs:sequence>
</xs:complexType>5.3.1.19 Subtypes of Built-in Types
The subtypes of the built-in DataTypes described in 5.3.1 are encoded as the base built-in DataType.
5.3.2 Decimal
A Decimal Value is a encoded as an xs:complexType with the following XML schema:
<xs:complexType name="Decimal">
<xs:sequence>
<xs:element name="TypeId" type="tns:NodeId" minOccurs="0" />
<xs:element name="Body" minOccurs="0">
<xs:complexType>
<xs:sequence>
<xs:element name="Scale" type="xs:short" />
<xs:element name="Value" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
The NodeId is always the NodeId of the Decimal DataType. When encoded in a Variant the Decimal is encoded as an ExtensionObject. Arrays of Decimals are Arrays of ExtensionObjects.
The Value is a base-10 signed integer with no limit on size. See 5.1.10 for a description of the Scale and Value fields.
5.3.3 Enumerations
Enumerations that are used as parameters in the Messages defined in OPC 10000-4 are encoded as xs:string with the following syntax:
<symbol>_<value>The elements of the syntax are described in Table 36.
| Field | Type | Description |
|---|---|---|
| <symbol> | String | The symbolic name for the enumerated value. |
| <value> | UInt32 | The numeric value associated with enumerated value. |
For example, the XML schema for the NodeClass enumeration is:
<xs:simpleType name="NodeClass">
<xs:restriction base="xs:string">
<xs:enumeration value="Unspecified_0" />
<xs:enumeration value="Object_1" />
<xs:enumeration value="Variable_2" />
<xs:enumeration value="Method_4" />
<xs:enumeration value="ObjectType_8" />
<xs:enumeration value="VariableType_16" />
<xs:enumeration value="ReferenceType_32" />
<xs:enumeration value="DataType_64" />
<xs:enumeration value="View_128" />
</xs:restriction>
</xs:simpleType>
Enumerations that are stored in a Variant are encoded as an Int32 value.
For example, any Variable could have a value with a DataType of NodeClass. In this case, the corresponding numeric value is placed in the Variant (e.g. NodeClass Object would be stored as a 1).
5.3.4 Arrays
One dimensional Array parameters are always encoded by wrapping the elements in a container element and inserting the container into the structure. The name of the container element should be the name of the parameter. The name of the element in the array shall be the type name.
For example, the Read service takes an array of ReadValueIds. The XML schema would look like:
<xs:complexType name="ListOfReadValueId">
<xs:sequence>
<xs:element name="ReadValueId" type="tns:ReadValueId"
minOccurs="0" maxOccurs="unbounded" nillable="true" />
</xs:sequence>
</xs:complexType>
The nillable attribute shall be specified because XML encoders will drop elements in arrays if those elements are empty.
Multi-dimensional Array parameters are encoded using the Matrix type defined in 5.3.1.17.
5.3.5 Structures
Structures are encoded as a xs:complexType with all of the fields appearing as a sequence of xs:elements. Each element has a name specified by the name of the field in the DataTypeDefinition. All elements have minOccurs set 0 to allow for compact XML representations. If an element is missing the DefaultValue for the field type is used. If the field type is a structure the DefaultValue is an instance of the structure with DefaultValues for each contained field.
The XML type for an element name is xs:name and it restricts the set of characters that are permitted. If a DataType name or its field names uses characters that are not permitted then the name encoding rules in 5.1.13 shall be used.
Types which have a NULL value defined shall have the nillable="true" flag set.For example, the Read service has a ReadValueId structure in the request. The XML schema would look like:
<xs:complexType name="ReadValueId">
<xs:sequence>
<xs:element name="NodeId" type="tns:NodeId"
minOccurs="0" nillable="true" />
<xs:element name="AttributeId" type="xs:int" minOccurs="0" />
<xs:element name="IndexRange" type="xs:string"
minOccurs="0" nillable="true" />
<xs:element name="DataEncoding" type="tns:NodeId"
minOccurs="0" nillable="true" />
</xs:sequence>
</xs:complexType>
5.3.6 Structures with optional fields
Structures with optional fields are encoded as a xs:complexType with all of the fields appearing as a sequence of xs:elements. The first element is a bit mask that specifies what fields are encoded. The bits in the mask are sequentially assigned to optional fields in the order they appear in the Structure. The rest of the elements have a name specified by the name of the field in the DataTypeDefinition.
To allow for compact XML, any field can be omitted from the XML so decoders shall assign DefaultValues based on the field type for any mandatory fields.
The xs:name attribute restricts the set of characters that are permitted. See 5.3.5 for instructions on how to handle invalid characters.
For example, the following Structure has one mandatory and two optional fields. The XML schema would look like:
<xs:complexType name="OptionalType">
<xs:sequence>
<xs:element name="EncodingMask" type="xs:unsignedLong" />
<xs:element name="X" type="xs:int" minOccurs="0" />
<xs:element name="O1" type="xs:int" minOccurs="0" />
<xs:element name="Y" type="xs:byte" minOccurs="0" />
<xs:element name="O2" type="xs:int" minOccurs="0" />
</xs:sequence>
</xs:complexType>
In the example above, the EncodingMask has a value of 3 if both O1 and O2 are encoded. Encoders shall set unused bits to 0 and decoders shall ignore unused bits.
If a Structure with optional fields is subtyped, the subtypes extend the EncodingMask defined for the parent.
5.3.7 Unions
Unions are encoded as an xs:complexType containing an xs:sequence with two entries.
The first entry in the sequence is the SwitchField xs:element and specifies a numeric value which identifies which element in the xs:choice is encoded. The name of the element may be any valid text.
The second entry in the sequence is an xs:choice which specifies the possible fields as xs:elements. The order in the xs:choice determines the value of the SwitchField when that choice is encoded. The first element has a SwitchField value of 1 and the last value has a SwitchField equal to the number of choices. The name of each xs:choice is the name of the field in the DataTypeDefinition.
No additional elements in the sequence are permitted. If the SwitchField is missing or 0 then the union has a NULL value. Encoders or decoders shall report an error for any SwitchField value greater than the number of defined union fields.
The name attribute restricts the set of characters that are permitted. See 5.3.5 for instructions on how to handle invalid characters.
For example, the following union has two fields. The XML schema would look like:
<xs:complexType name="Type1">
<xs:sequence>
<xs:element name="SwitchField"
type="xs:unsignedInt" minOccurs="0"/>
<xs:choice>
<xs:element name="Field1" type="xs:int" minOccurs="0"/>
<xs:element name="Field2" type="tns:Field2" minOccurs="0"/> </xs:choice>
</xs:sequence>
</xs:complexType>
5.3.8 Messages
Messages are encoded as an xs:complexType. The parameters in each Message are serialized in the same way the fields of a Structure are serialized.
5.4 OPC UA JSON
5.4.1 General
The JSON DataEncoding was developed to allow OPC UA applications to interoperate with web and enterprise software that use this format. The OPC UA JSON DataEncoding defines standard JSON representations for all built-in types.
The JSON format is defined in IETF RFC 8259. It is partially self-describing because each field has a name encoded in addition to the value, however, JSON has no mechanism to qualify names with namespaces.
The JSON format does not have a published standard for a schema that can be used to describe the contents of a JSON document. However, the schema mechanisms defined in this document can be used to describe JSON documents. Specifically, the DataTypeDescription structure defined in OPC 10000-3 can define any JSON document that conforms to the rules described below.
There are two important use cases for the JSON encoding: cloud applications which consume PubSub messages and JavaScript Clients (JSON is the preferred serialization format for JavaScript). For the cloud application use case, the PubSub message is self-contained which implies it cannot contain numeric references to an externally defined namespace table. Cloud applications also often rely on scripting languages to process the incoming messages so artefacts in the DataEncoding that exist to ensure fidelity during decoding are not necessary. For this reason, this DataEncoding identifies some the artefacts which can be removed to meet the needs of cloud applications. Applications, such as JavaScript Clients, which use the DataEncoding for communication with other OPC UA applications require the artefacts.
The CompactEncoding omits all fields in Structure values with a value equal to the default value for the type. The VerboseEncoding includes all of these fields.
The CompactEncoding and VerboseEncoding replace the ReversibleEncoding and NonReversibleEncoding. The differences are described in Annex H. The VerboseEncoding also supports the RawData mode defined in OPC 10000-14. In RawData mode, encoders shall omit the following fields:
UaType (see 5.4.2.17 and 5.4.2.18);
UaTypeId (see 5.4.2.16);
Decoders may not be able to process streams encoding in RawData mode unless they have access to the associated metadata. These fields are not omitted when serialization uses abstract DataTypes such as Structure (i.e. ExtensionObject) or BaseDataType (i.e. Variant). OPC 10000-14 specifies the behaviour if a Publisher is misconfigured with metadata that uses abstract DataTypes.
5.4.2 Built-in Types
5.4.2.1 General
Any value for a nullable Built-In type that is NULL shall be encoded as the JSON literal 'null' if the value is an element of a JSON array. If the NULL value is for a field within a JSON object, the field shall be omitted when using the CompactEncoding. When using the VerboseEncoding, the field is encoded as the JSON literal 'null'.
Any non-nullable built-in type shall be encoded if it is an element of an array. When using the CompactEncoding, the field of a Structure or Union is omitted if value is equal to the default value for the built-in type.
Note that JSON objects are unordered sets of name-value pairs. When a built-in type is encoded as a JSON object, the order of fields specified is not preserved.
5.4.2.2 Boolean
A Boolean value shall be encoded as the JSON literal 'true' or 'false'.
5.4.2.3 Integer
Integer values other than Int64 and UInt64 shall be encoded as a JSON number.
Int64 and UInt64 values shall be formatted as a decimal number encoded as a JSON string
(See the XML encoding of 64-bit values described in 5.3.1.3).
5.4.2.4 Floating-point
Normal Float and Double values shall be encoded as a JSON number.
Special floating-point numbers such as positive infinity (INF), negative infinity (-INF) and not-a-number (NaN) shall be represented by the values "Infinity", "-Infinity" and "NaN" encoded as a JSON string. See 5.2.2.3 for more information on the different types of special floating-point numbers.
5.4.2.5 String
String values shall be encoded as JSON strings.
Any characters which are not allowed in JSON strings are escaped using the rules defined in IETF RFC 8259.
Strings with embedded nulls ('\u0000') are not guaranteed to be interoperable because not all DevelopmentPlatforms can handle Strings with embedded nulls. For this reason, embedded nulls are not recommended. Encoders may encode Strings with embedded nulls. Decoders shall read all bytes in String; however, decoders may truncate the String at the first embedded null before passing it on to the application.
5.4.2.6 DateTime
DateTime values shall be formatted as specified by ISO 8601-1 and encoded as a JSON string.
DateTime values which exceed the minimum or maximum values supported on a platform shall be encoded as "0001-01-01T00:00:00Z" or "9999-12-31T23:59:59Z" respectively. During decoding, these values shall be converted to the minimum or maximum values supported on the platform.
ISO 8601-1 DateType values may specify an arbitrary number of decimal places representing fractions of seconds. Encoders shall support as many decimal places required to represent the full range of the DateTime type on their DevelopmentPlatform. Decoders may truncate decimal places that exceed the range supported by the DateTime type on their DevelopmentPlatform.
DateTime values equal to "0001-01-01T00:00:00Z" are considered to be NULL values.
5.4.2.7 Guid
Guid values shall be formatted as described in 5.1.3 and encoded as a JSON string.
5.4.2.8 ByteString
ByteString values shall be formatted as a Base64 text and encoded as a JSON string.
Any characters which are not allowed in JSON strings are escaped using the rules defined in IETF RFC 8259.
5.4.2.9 XmlElement
XmlElement value shall be encoded as a String as described in 5.4.2.5.
5.4.2.10 NodeId
NodeId values shall be encoded as a JSON string using the format defined in 5.1.12. NodeIds in NamespaceIndex 0 use the <identifier> form. All other NodeIds use the <namespace-uri> form.
The first abnormal state occurs when the encoder cannot map a NamespaceIndex to a NamespaceUri. In this case, the encoder shall encode the NamespaceIndex using the <namespace-index> form. The decoder shall pass this NamespaceIndex to the application.
The second abnormal state occurs when the decoder cannot convert a NamespaceUri to a NamespaceIndex. If this occurs the decoder shall set the NamespaceIndex to 0, the IdType to String and the Identifier to the JSON string.
5.4.2.11 ExpandedNodeId
ExpandedNodeId values shall be encoded as a JSON string using the format defined in 5.1.12. The NodeId portion of the ExpandedNodeId uses the rules from 5.4.2.10.ExpandedNodeIds with a ServerIndex of 0 are encoded using the <node-id> form. All other ExpandedNodeIds use the <server-uri> form unless the first abnormal state occurs as described below.
The first abnormal state occurs when the encoder cannot map a ServerIndex to a ServerUri. In this case, the encoder shall encode the ServerIndex using the <server-index> form. The decoder shall pass this ServerIndex to the application.
The second abnormal state occurs when the decoder cannot convert a ServerUri to a ServerIndex. If this occurs the decoder shall set the ServerIndex to 0, the NamespaceIndex to 0, the IdType to String and the Identifier to the JSON string.
When the ServerIndex is 0, decoders shall replace a NamespaceUri with a NamespaceIndex when a mapping exists or if a mapping can be created. If no mapping exists or one cannot be created the NamespaceUri is stored in the NamespaceUri field of the ExpandedNodeId.
5.4.2.12 StatusCode
StatusCode values shall be encoded as a JSON object with the fields defined in Table 37.
| Name | Description |
|---|---|
| Code | The numeric code encoded as a JSON number. The Code is omitted if the numeric code is 0 (Good). |
| Symbol | The string literal associated with the numeric code encoded as JSON string. e.g. 0x80AB0000 has the associated literal "BadInvalidArgument". Any InfoBits in the StatusCode are ignored when looking up the symbol. If the string literal is not known to the encoder the field is omitted. The field is omitted in the CompactEncoding. The field is omitted if the numeric code is 0 (Good). The recommended string literals are defined in A.2. |
5.4.2.13 DiagnosticInfo
DiagnosticInfo values shall be encoded as a JSON object with the fields shown in Table 38.
| Name | Data Type | Description |
|---|---|---|
| SymbolicId | Int32 | A symbolic name for the status code. The default value is -1. It is not encoded if the value is -1. |
| NamespaceUri | Int32 | A namespace that qualifies the symbolic id. The default value is -1. It is not encoded if the value is -1. |
| Locale | Int32 | The locale used for the localized text. The default value is -1. It is not encoded if the value is -1. |
| LocalizedText | Int32 | A human readable summary of the status code. The default value is -1. It is not encoded if the value is -1. |
| AdditionalInfo | String | Detailed application specific diagnostic information. The default value is null. It is not encoded if the value is null. |
| InnerStatusCode | StatusCode | A status code provided by an underlying system. The default value is Good. It is not encoded if the value is Good. |
| InnerDiagnosticInfo | DiagnosticInfo | Diagnostic info associated with the inner status code. The default value is null. It is not encoded if the value is null. |
The SymbolicId, NamespaceUri, Locale and LocalizedText fields are encoded as JSON numbers which reference the StringTable contained in the ResponseHeader.
DiagnosticInfo is recursive and unlimited recursion could result in stack overflow errors even if the message size is less than the maximum allowed. Decoders shall support at least 4 recursion levels and are not expected to support more than 10. Decoders shall report an error if the number of recursion levels exceeds what it supports.
5.4.2.14 QualifiedName
QualifiedName values shall be encoded as a JSON string using the format defined in 5.1.12.
The form with the NamespaceIndex is not allowed unless there is an encoding error. This can occur when the encoder cannot map a NamespaceIndex to a NamespaceUri. In this case, the encoder shall encode the NamespaceIndex using the <namespace-index> form. The decoder shall pass this NamespaceIndex to the application.
A second abnormal state occurs when the decoder cannot convert a NamespaceUri to a NamespaceIndex. If this occurs the decoder shall set the NamespaceIndex to 0 and the Name to the raw JSON string that includes the NamespaceUri that cannot be decoded.
5.4.2.15 LocalizedText
LocalizedText values shall be encoded as a JSON object with the fields shown in Table 39.
| Name | Description |
|---|---|
| Locale | The Locale portion of LocalizedText values shall be encoded as a JSON string. The field is not encoded if it is null or empty. |
| Text | The Text portion of LocalizedText values shall be encoded as a JSON string. The field is not encoded if it is null or empty. |
5.4.2.16 ExtensionObject
The ExtensionObject is encoded as a JSON object as described in:
Structure (see 5.4.6);
Structure with optional fields (see 5.4.7);
Union (see 5.4.8);
with the UaTypeId field inserted into the JSON object.
Decoders shall report decoding errors to the application if a JSON object has multiple fields with the same name.
The UaEncoding and UaBody fields are only used when UA Binary or UA XML encoded Structures are serialized. Only the fields in Table 40 are present if these fields are used.
The JSON object fields used for an ExtensionObject are in Table 40.
| Name | Description |
|---|---|
| UaTypeId | A NodeId formatted using the rules in 5.4.2.10. This is the NodeId of a DataType Node. |
| UaEncoding | A JSON number that represents the format of the UaBody field. A value of 1 indicates UA Binary data is encoded in the UaBody field. A value of 2 indicates UA XML data is encoded in the UaBody field. This field is omitted for JSON encoded Structures. |
| UaBody | A ByteString containing an UA Binary or UA XML encoded Structure. This field is omitted for JSON encoded Structures. |
Encoders, when allowed by the DevelopmentPlatform, should write the UaTypeId first. Decoders shall accept the UaTypeId in any position.
The default value for an ExtensionObject is serialized as an empty JSON object in the VerboseEncoding and omitted in the CompactEncoding.
5.4.2.17 Variant
Variant values shall be encoded as a JSON object with the fields shown in Table 41.
| Name | Description |
|---|---|
| UaType | The built-in type for the value contained in the Body (see Table 1) encoded as JSON number. |
| Value | If the value is a scalar, it is encoded using the rules for type specified for the Type. If the value is a one-dimensional array it is encoded as JSON array (see 5.4.5). Multi-dimensional arrays are encoded as a JSON array containing all elements. The mapping of a multidimensional array to a flat list is described in 5.2.2.16. The field is not encoded if the value is a NULL for nullable built-in types (see Table 1). |
| Dimensions | The dimensions of the array encoded as a JSON array of JSON numbers. |
Encoders, when allowed by the DevelopmentPlatform, should write the UaType first. Decoders shall accept the UaType field in any position.
5.4.2.18 DataValue
DataValue values shall be encoded as a JSON object with the fields shown in Table 42.
The DataValue adds additional fields to a Variant (see 5.4.2.17).
| Name | Data Type | Description |
|---|---|---|
| UaType | Byte | See the UaType field in the Variant. |
| Value | * | See the Value field in the Variant. |
| Dimensions | UInt32 | See the Dimensions field in the Variant. |
| Status | StatusCode | The status associated with the value. Not encoded if the value is Good (0). |
| SourceTimestamp | DateTime | The source timestamp associated with the value. Not encoded if the value is DateTime.MinValue. |
| SourcePicoseconds | UInt16 | The number of 10 Picosecond intervals for the SourceTimestamp. Not encoded if the value is 0. |
| ServerTimestamp | DateTime | The Server timestamp associated with the value. Not encoded if the value is DateTime.MinValue. |
| ServerPicoseconds | UInt16 | The number of 10 Picosecond intervals for the ServerTimestamp. Not encoded if the value is 0. |
5.4.3 Decimal
Decimal values shall be encoded as a JSON object with the fields in Table 43.
| Name | Description |
|---|---|
| Scale | A JSON number with the scale applied to the Value. |
| Value | A JSON string with the Value encoded as a base-10 signed integer. See the XML encoding of Integer values described in 5.3.1.3. |
See 5.1.10 for a description of the Scale and Value fields.
When encoding in a Variant, a Decimal value shall be encoded as an ExtensionObject with the JSON object in Table 43 as the Body. The TypeId shall be the NodeId of the Decimal DataType and the Encoding shall be 0.
5.4.4 Enumerations
5.4.4.1 Compact
Enumeration values shall be encoded as a JSON number.
When an Enumeration is encoded in a Variant the Type field is Int32.
5.4.4.2 Verbose
Enumeration values are encoded as a JSON string with the following format:
<name>_<value>Where the name is the enumeration literal and the value is the numeric value.
If the literal is not known to the encoder, the numeric value is encoded as a JSON string.
When an Enumeration is encoded in a Variant the Type field is a Int32 and the value is encoded as a JSON number.
5.4.5 Arrays
One-dimensional Arrays shall be encoded as JSON arrays.
If an element is NULL, the element shall be encoded as the JSON literal 'null'.
Otherwise, the element is encoded according to the rules defined for the type.
Multidimensional Arrays are encoded as JSON object with the fields defined in Table 44.
| Name | Description |
|---|---|
| Array | Multi-dimensional arrays are encoded as a one-dimensional JSON array which is reconstructed using the value of the Dimensions field (see 5.2.2.16). |
| Dimensions | The dimensions of the array encoded as a JSON array of JSON numbers. |
5.4.6 Structures
Structures shall be encoded as JSON objects.
Note that JSON objects are unordered sets of name-value pairs. The order specified by the DataTypeDefinition is not preserved when a Structure is serialized in JSON.
Fields which are NULL or have a default value shall be encoded using the rules shown in Table 45.
| Field Value | Compact | Verbose |
|---|---|---|
| NULL | Omitted | JSON null |
| Default Value | Omitted | Default Value |
For example, instances of the structures:
struct Type2
{
Int32 A;
Int32 B;
Char* C;
};
struct Type1
{
Int32 X;
Int32 NoOfY;
Type2* Y;
Int32 Z;
};The CompactEncoding is represented in JSON as:
{
"X":1234,
"Y":[ { "A":1, "B":2, "C":"Hello" }, { "A":3, "B":4 } ],
"Z":5678
}Where "C" is omitted from the second Type2 instance because it has a NULL value.
The VerboseEncoding is represented in JSON as:
{
"X":1234,
"Y":[ { "A":1, "B":2, "C":"Hello" }, { "A":3, "B":4, "C":null } ],
"Z":5678
}Where "C" in the second Type2 instance has a JSON null value.
Code generators should ensure that the special field names (UaType, UaTypeId and EncodingMask) are not permitted in Structures.
5.4.7 Structures with optional fields
Structures with optional fields shall be encoded as JSON objects as shown in Table 46.
Note that JSON objects are unordered sets of name-value pairs. The order specified by the DataTypeDefinition is not preserved when a Structure is serialized in JSON. The EncodingMask is not guaranteed to appear as the first field.
In the VerboseEncoding the bits in the EncodingMask are determined by the presence of a field in the JSON object. In the CompactEncoding, EncodingMask indicates which fields are specified because fields are omitted because they have a default value.
| Name | Description |
|---|---|
| EncodingMask | A bit mask indicating what fields are encoded in the structure (see 5.2.7). This mask is encoded as a JSON number. The bits are sequentially assigned to optional fields in the order that they are defined. This field is omitted in the VerboseEncoding |
| <FieldName> | The field in structure encoded according to the rules defined for their DataType. One entry may exist for each mandatory field and each optional field that is present. |
Fields which are NULL or have a default value shall be encoded using the rules shown in Table 47.
| Field Value | Field Type | Compact | Verbose |
|---|---|---|---|
| NULL | Mandatory | Omitted | JSON null |
| Default Value | Mandatory | Omitted | Default Value |
| NULL | Optional (Present) | Omitted | JSON null |
| Default Value | Optional (Present) | Omitted | Default Value |
| NULL | Optional (Omitted) | Omitted | Omitted |
| Default Value | Optional (Omitted) | Omitted | Omitted |
If a Structure with optional fields is subtyped, the subtypes extend the EncodingMask defined for the parent.
The following is an example of a structure with optional fields using C++ syntax:
struct TypeA
{
Int32 X;
Int32* O1;
SByte Y;
Int32* O2;
};
O1 and O2 are optional fields where a NULL indicates that the field is not present.
Assume that O1 is not specified and the value of O2 is 0.
The CompactEncoding would be:
{ "EncodingMask": 2, "X": 1, "Y": 2 }Where decoders would assign the default value of 0 to O2 since the mask bit is set even though the field was omitted (this is the behaviour defined for the Int32 DataType). Decoders would mark O1 as 'not specified'.
The VerboseEncoding would be:
{ "X": 1, "Y": 2, "O2": 0 }Encoders, when allowed by the DevelopmentPlatform, should write the EncodingMask first. Decoders shall accept the EncodingMask in any position.
Code generators should ensure that the special field names (UaType, UaTypeId and EncodingMask) are not permitted in Structures with option field.
5.4.8 Unions
Unions shall be encoded as JSON objects as shown in Table 48.
Note that JSON objects are unordered sets of name-value pairs. The order specified by the DataTypeDefinition is not preserved when a Union is serialized in JSON.
| Name | Description |
|---|---|
| SwitchField | This field is only present in the CompactEncoding. The identifier for the field in the Union which is encoded as a JSON number. The valid values for this field follow the conventions defined in 5.2.8. A Union with no field specified is encoded as an empty JSON object. |
| <FieldName> | The value of the field encoded using the rules that apply to the DataType. The name of field in the JSON object is the name of the field in the DataTypeDefinition. |
For example, instances of the union:
struct Union1
{
Byte Selector;
{
Int32 A;
Double B;
Char* C;
}
Value;
};
would be represented in the CompactEncoding as:
{ "SwitchField":2, "B":3.1415 }and would be represented in the VerboseEncoding as:
{ "B":3.1415 }5.4.9 Messages
Messages are encoded as ExtensionObjects (see 5.4.2.16).