
5 General information to DEXPI and OPC UA
5.1 Introduction to DEXPI
This introductionto the DEXPI group is part of the DEXPI specification document and was added here for readability and completeness purposes. For more information refer to the DEXPI specification 1.2 (see section 2 - Normative references).
5.1.1 About DEXPI
The DEXPI group (Data EXchange for the Process Industry) is a working party of the ProcessNet initiative under the lead of Dechema. ProcessNet describes itself as:
"ProcessNet is the German platform for chemical engineering with more than 5,000 members. Experts from the sciences, industry and administration exchange ideas and experience, discuss current topics and identify new scientific trends. ProcessNet is a joint initiative of DECHEMA and VDI-GVC.
ProcessNet organises numerous events targeting the interdisciplinary and cross-sectoral exchange of information. The most prominent conference is the ProcessNet Annual Meeting attracting more than 1,000 participants. The wide variety of thematically structured committees deal with scientific and technical problems and issues of paramount technological and societal relevance, they also trigger funding policy initiatives. ProcessNet is the national contact point for international co-operations. Participation in ProcessNet is open to all members of DECHEMA and/or VDI-GVC." (Source: www.processnet.org)
5.1.2 Motivation for the DEXPI
Due to the lack of interoperability between Computer Aided Engineering (CAE) (and other) systems, companies today face high efforts in data exchange while working together to execute projects for planning, construction and operation of process plants. Parties typically exchanging data in such projects are EP/EPCs, owner-operators, and vendors, but also site services and authorities. One of the main reasons for this high effort is the lack of an agreed understanding across the different systems, e.g. by means of a commonly used standard for data exchange within the process industry. To become more efficient during planning, construction and operation of plants, a data exchange model based on the ISO 15926 standard shall be established.
5.1.3 Objectives
The objective is to develop and promote a general method for data exchange, data interoperability and data integration for the process industry covering all phases of the lifecycle of a (petro-)chemical plant, ranging from specification of functional requirements to assets in operation. This method shall cover formats and content to address various problems seen today:
- Avoid format conversions (and thereby data loss) when passing engineering data and documents across CAE system boundaries.
- Make handover of engineering data during and at the end of a project easy and cost-effective.
- Reduce data exchange barriers between different CAE systems or different customizations of the same CAE systems. Support long-term storage of plant data in a CAE system-independent format. Today's commonly used standard formats like PDF don't support value-added improvements or at best, they do so insufficiently.
- Simplify co-existence of different CAE systems within a company, e.g. due to mergers/acquisitions or different priorities in different business units.
5.1.4 Expectations
EP/EPCs, suppliers and owner operators want to minimize the cost for handling engineering data during planning, construction and operation of process plants between different CAE systems and they want to create opportunities for new value-added functions based on the available engineering data. Therefore, the CAE vendors will implement a valid global standard for data exchange into their CAE systems. In the first phase, data exchange will cover the graphics and topology of the full Piping and Instrumentation Diagram (P&ID) and attributes of the discrete P&ID components.
The involved owner/operator companies from the DEXPI working group will define a common data model which is based on the ISO 15926 standard. The resulting data model will be aligned with other projects in the global ISO 15926 community, e.g. within Fiatech. The CAE vendors will implement this common data model as the basis for data exchange and will deliver it as part of their default system configuration. In addition, it is expected that CAE vendors agree on a common exchange format for the graphical representation of a P&ID and implement the result in their systems as well. The involved companies expect constructive team work by the CAE vendors during the definition of the common ISO 15926 conformant data model.
Objective of the first phase of the initiative is the transfer of a P&ID from one P&ID system to another P&ID system. The data transfer must include graphics, symbols, topology, all engineering attributes, enumerations, select lists etc. to enable seamless continuation of work on the P&ID in the destination system. Transfer of engineering data over the full life cycle of a plant between different CAE tools from simulation to basic/detail engineering up to operations and maintenance may be covered in subsequent phases.
5.2 Introduction to OPC Unified Architecture
5.2.1 What is OPC UA?
OPC UA is an open and royalty-free set of standards designed as a universal communication protocol. While there are numerous communication solutions available, OPC UA has key advantages:
A state-of-theart security model (see OPC 10000-2).
A fault-tolerant communication protocol.
An information modelling framework that allows application developers to represent their data in a way that makes sense to them.
OPC UA has a broad scope which delivers economies of scale for application developers. This means that a larger number of high-quality applications at a reasonable cost are available. When combined with semantic models such as DEXPI, OPC UA makes it easier for end users to access data via generic commercial applications.
The OPC UA model is scalable from small devices to ERP systems. OPC UA Servers process information locally and then provide that data in a consistent format to any application requesting data - ERP, MES, PMS, Maintenance Systems, HMI, Smartphone or a standard Browser, for example. For a more complete overview, see OPC 10000-1.
5.2.2 Basics of OPC UA
As an open standard, OPC UA is based on standard internet technologies, like TCP/IP, HTTP, Web Sockets.
As an extensible standard, OPC UA provides a set of Services (see OPC 10000-4) and a basic information model framework. This framework provides an easy manner for creating and exposing vendor defined information in a standard way. More importantly all OPC UA Clients are expected to be able to discover and use vendor-defined information. This means OPC UA users can benefit from the economies of scale that come with generic visualization and historian applications. This specification is an example of an OPC UA Information Model designed to meet the needs of developers and users.
OPC UA Clients can be any consumer of data from another device on the network to browser-based thin clients and ERP systems. The full scope of OPC UA applications is shown in Figure 1.
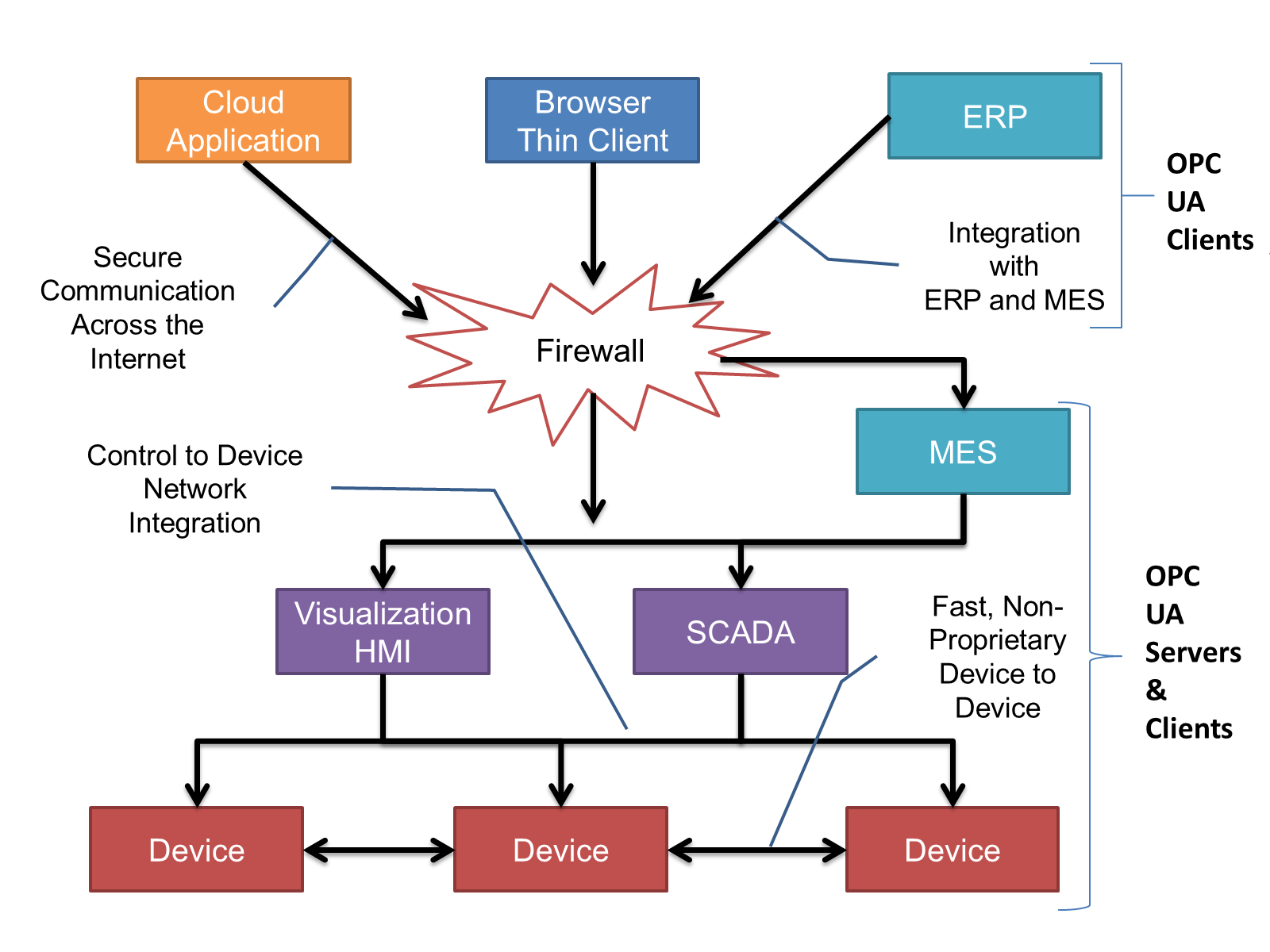
OPC UA provides a robust and reliable communication infrastructure having mechanisms for handling lost messages, failover, heartbeat, etc. With its binary encoded data, it offers a high-performing data exchange solution. Security is built into OPC UA as security requirements become more and more important especially since environments are connected to the office network or the internet and attackers are starting to focus on automation systems.
5.2.3 Information modelling in OPC UA
5.2.3.1 Concepts
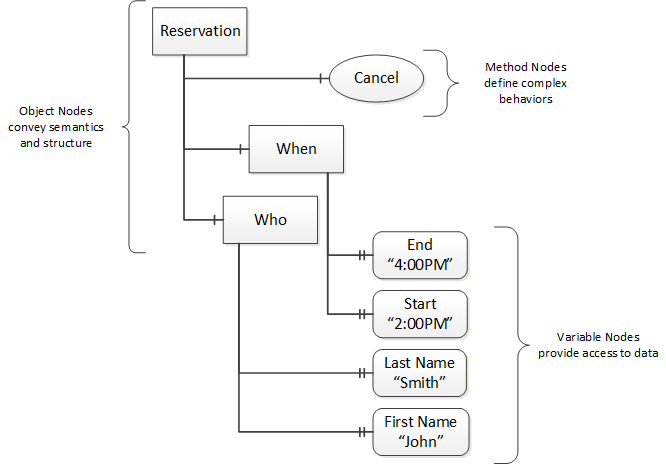
OPC UA provides a framework that can be used to represent complex information as Objects in an AddressSpace which can be accessed with standard services. These Objects consist of Nodes connected by References. Different classes of Nodes convey different semantics. For example, a Variable Node represents a value that can be read or written. The Variable Node has an associated DataType that can define the actual value, such as a string, float, structure etc. It can also describe the Variable value as a variant. A Method Node represents a function that can be called. Every Node has a number of Attributes including a unique identifier called a NodeId and non-localized name called as BrowseName. An Object representing a ‘Reservation’ is shown in Figure 2.
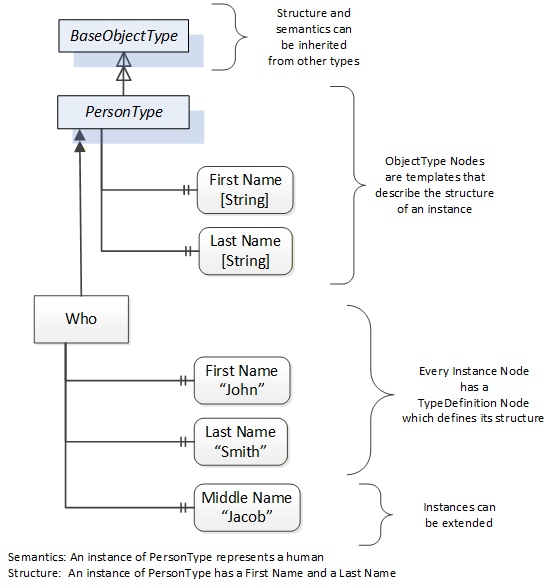
Object and Variable Nodes represent instances and they always reference a TypeDefinition (ObjectType or VariableType) Node which describes their semantics and structure. Figure 3 illustrates the relationship between an instance and its TypeDefinition.
The type Nodes are templates that define all the children that can be present in an instance of the type. In the example in Figure 3 the PersonType ObjectType defines two children: First Name and Last Name. All instances of PersonType are expected to have the same children with the same BrowseNames. Within a type the BrowseNames uniquely identify the children. This means Client applications can be designed to search for children based on the BrowseNames from the type instead of NodeIds. This eliminates the need for manual reconfiguration of systems if a Client uses types that multiple Servers implement.
OPC UA also supports the concept of sub-typing. This allows a modeller to take an existing type and extend it. There are rules regarding sub-typing defined in OPC 10000-3, but in general they allow the extension of a given type or the restriction of a DataType. For example, the modeller may decide that the existing ObjectType in some cases needs an additional Variable. The modeller can create a subtype of the ObjectType and add the Variable. A Client that is expecting the parent type can treat the new type as if it was of the parent type. Regarding DataTypes, subtypes can only restrict. If a Variable is defined to have a numeric value, a sub type could restrict it to a float.
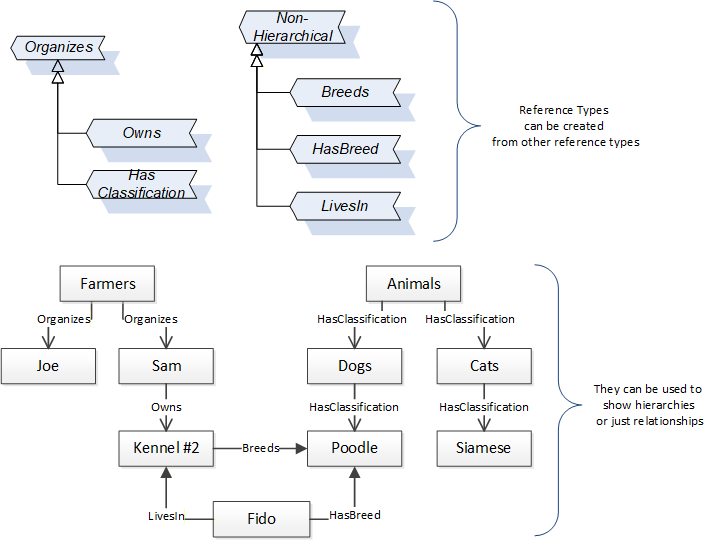
References allow Nodes to be connected in ways that describe their relationships. All References have a ReferenceType that specifies the semantics of the relationship. References can be hierarchical or non-hierarchical. Hierarchical references are used to create the structure of Objects and Variables. Non-hierarchical are used to create arbitrary associations. Applications can define their own ReferenceType by creating subtypes of an existing ReferenceType. Subtypes inherit the semantics of the parent but may add additional restrictions. Figure 4 depicts several References, connecting different Objects.
The figures above use a notation that was developed for the OPC UA specification. The notation is summarized in Figure 5. UML representations can also be used; however, the OPC UA notation is less ambiguous because there is a direct mapping from the elements in the figures to Nodes in the AddressSpace of an OPC UA Server.
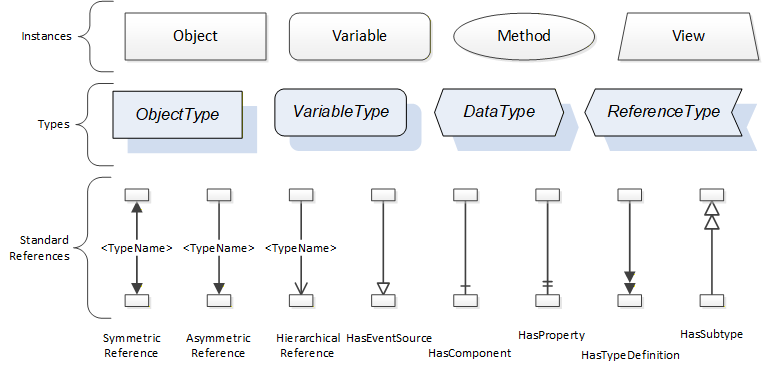
A complete description of the different types of Nodes and References can be found in OPC 10000-3 and the base structure is described in OPC 10000-5.
OPC UA specification defines a very wide range of functionality in its basic information model. It is not expected that all Clients or Servers support all functionality in the OPC UA specifications. OPC UA includes the concept of Profiles, which segment the functionality into testable certifiable units. This allows the definition of functional subsets (that are expected to be implemented) within a companion specification. The Profiles do not restrict functionality, but generate requirements for a minimum set of functionality (see OPC 10000-7)
5.2.3.2 Namespaces
OPC UA allows information from many different sources to be combined into a single coherent AddressSpace. Namespaces are used to make this possible by eliminating naming and id conflicts between information from different sources. Namespaces in OPC UA have a globally unique string called a NamespaceUri and a locally unique integer called a NamespaceIndex. The NamespaceIndex is only unique within the context of a Session between an OPC UA Client and an OPC UA Server. The Services defined for OPC UA use the NamespaceIndex to specify the Namespace for qualified values.
There are two types of values in OPC UA that are qualified with Namespaces: NodeIds and QualifiedNames. NodeIds are globally unique identifiers for Nodes. This means the same Node with the same NodeId can appear in many Servers. This, in turn, means Clients can have built in knowledge of some Nodes. OPC UA Information Models generally define globally unique NodeIds for the TypeDefinitions defined by the Information Model.
QualifiedNames are non-localized names qualified with a Namespace. They are used for the BrowseNames of Nodes and allow the same names to be used by different information models without conflict. TypeDefinitions are not allowed to have children with duplicate BrowseNames; however, instances do not have that restriction.
5.2.3.3 Companion Specifications
An OPC UA companion specification for an industry-specific vertical market describes an Information Model by defining ObjectTypes, VariableTypes, DataTypes and ReferenceTypes that represent the concepts used in the vertical market, and potentially also well-defined Objects as entry points into the AddressSpace.