Errata exists for this version of the document.
StatusCodes for an Aggregate value shall take into account the values used to calculate them. In addition, the configuration parameters PercentDataGood and PercentDataBad allow the client to control how this calculation is done if supported by the Server.
If an Aggregate operates on raw values (e.g. Average) the calculation is done by counting values. If an Aggregate operates on raw values but can also return a Bounding Value then the Bounding Values are included in the count when computing the StatusCode. If an Aggregate does any sort of a time weighted calculation (e.g. TimeAverage or TimeAverage2) then the StatusCode calculation shall also be time weighted.
For purposes of calculating time weighted StatusCodes each interval shall be divided into regions of Good or Bad data. Creating these regions requires that the bounding values be calculated for each interval and the type of bounding value depends on the Aggregate.
If TreatUncertainAsBad = False then Uncertain regions are included with the Good regions when calculating the above ratios, if the TreatUncertainAsBad = True then the Uncertain regions are included as Bad regions. The StatusCode of the value is still treated as Uncertain when the StatusCode for the result is calculated. If no Bad regions are in the interval then the StatusCode for the interval is Good. For any intervals containing regions where the StatusCodes are Bad, the total duration of all Bad regions is calculated and divided by the width of the interval. The resulting ratio is multiplied by 100 and compared to the PercentDataBad parameter. The StatusCode for the interval is Bad if the ratio is greater than or equal to the PercentDataBad parameter. For any interval which is not Bad, the total duration of all Good regions is then calculated and divided by the width of the interval. The resulting ratio is multiplied by 100 and compared to the PercentDataGood parameter. The StatusCode for the interval is Good if the ratio is greater than or equal to the PercentDataGood parameter. If for an interval neither ratio applies then that interval is Uncertain_DataSubNormal.
If there is no data in the interval and the interval is inside the range [start of data, end of data] and the Aggregate return data type is raw data type then the StatusCodes for the interval will be Bad_NoData unless an alternate status code is defined for a specific Aggregate.
The width of an interval is the ProcessingInterval unless it is a partial interval (i.e. has the Partial bit set). In these cases, the width is the time used when calculating the partial interval.
Subclauses 5.4.3.2.2 and 5.4.3.2.3 include diagrams that illustrate a request and data series. The colour of the time axis indicates the status for different regions. Red indicates Bad, green indicates Good and orange indicates Uncertain. These examples assume TreatUncertainAsBad = False.
Figure 2 illustrates a data series for Variable with Stepped = False and an Aggregate that uses Simple Bounding Values. The request being processed has a Start Time that falls before the first point in the series and an End Time that does not fall on an integer multiple of the ProcessingInterval.
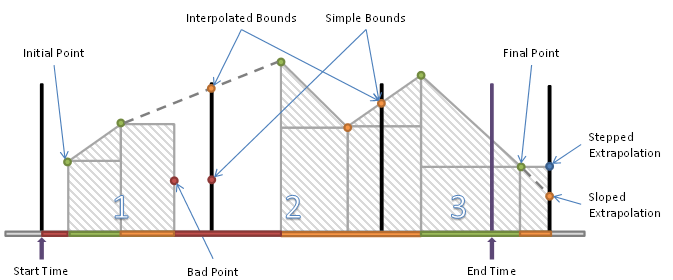
Figure 2 – Variable with Stepped = False and Simple Bounding Values
The first interval has four regions:
- the period before the first data point;
- the period between the first and second where SlopedInterpolation can be used;
- the period between the second and third point where SteppedInterpolation is used;
- the period after the Bad point where no data exists.
A region is Uncertain if a region ends in a Bad or Uuncertain value and SlopedInterpolation is used. The end point has no effect on the region if SteppedInterpolation is used.
The second interval has three regions:
- the period before the first Good data point where no data exists;
- the period between the first and second where SlopedInterpolation can be used;
- the period between the second point and the bound calculated with SlopedInterpolation.
The third interval has three regions:
- the period between the simple bound and the first data point;
- the period between the first point and an interpolated point that falls on the end time;
- the period after the end time which is ignored.
This is a partial region and the data after the end time is not used, however, if sloped interpolation is used and the point after the endpoint is Uncertain then the region between the last point and the end time will be Uncertain.
Figure 3 illustrates a data series for Variable with Stepped = True and an Aggregate that uses Interpolated Bounding Values. The request being processed has a Start Time that falls before the first point in the series and an End Time that does not fall on an integer multiple of the ProcessingInterval.

Figure 3 – Variable with Stepped = True and Interpolated Bounding Values
The first interval has three regions:
- the period before the first data point;
- the period between the first and second where SteppedInterpolation is used;
- the period between the second and the interpolated end bound.
The Bad point is ignored because of the interpolated end bound but this does create Uncertain regions. If SlopedInterpolation was used the Uncertain region would start at the second point. In this case, it only starts when the first Bad value is ignored.
The second interval has three regions:
- the period between the start bound and the first data point;
- the period between the first and second where SteppedInterpolation is used;
- the period between the second and the interpolated end bound.
The third interval has three regions:
- the period between the interpolated bound and the first data point;
- the period between the first point and an interpolated point that falls on the end time;
- the period after the end time which is ignored.
This is a partial region and the data after the end time is not used.