As shown in Figure 3, the IP configuration is modelled as individual Variables.
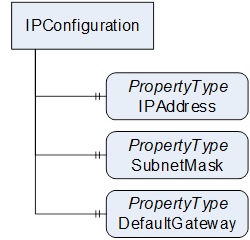
Figure 3 – Example of individual Variables
The advantages of this approach are that the complex structure of the data is visible in the AddressSpace. A generic Client can easily access the data without knowledge of user-defined DataTypes and the Client can access individual parts of the structured data. The information model may add additional information to parts of the structure (like engineering unit or precision information) or reference the individual parts of the structure from other places. Clients can write individual parts of the structure without changing other parts.
The disadvantages of this approach are that accessing the individual data does not provide any transactional context and each provides an individual timestamp. In the worst case, a Client may read part of the IP configuration before a change and other parts after a change of the configuration and therefore get an inconsistent configuration. For a specific Client the Server first has to convert the data and the Client has to convert the data, again, to get the data structure the underlying system provides. When writing the data, each part is written individually, so a part of the configuration may be accepted while other parts are invalid and rejected, leading to an unwanted configuration.