OPC UA allows to model structured data in different ways. As a simple example, an IP-configuration may consist of an IP-Address, a Subnet-Mask, and a Default-Gateway.
This may be modelled as
- Individual Variables
- Structured DataType and one Variable using the DataType
- Structured DataType and one Variable and individual Variables as subvariables
- Methods
- Events
As shown in Figure 3, the IP configuration is modelled as individual Variables.
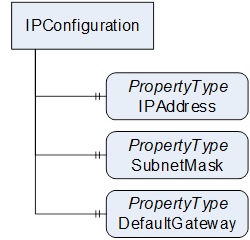
Figure 3 – Example of individual Variables
The advantages of this approach are that the complex structure of the data is visible in the AddressSpace. A generic Client can easily access the data without knowledge of user-defined DataTypes and the Client can access individual parts of the structured data. The information model may add additional information to parts of the structure (like engineering unit or precision information) or reference the individual parts of the structure from other places. Clients can write individual parts of the structure without changing other parts.
The disadvantages of this approach are that accessing the individual data does not provide any transactional context and each provides an individual timestamp. In the worst case, a Client may read part of the IP configuration before a change and other parts after a change of the configuration and therefore get an inconsistent configuration. For a specific Client the Server first has to convert the data and the Client has to convert the data, again, to get the data structure the underlying system provides. When writing the data, each part is written individually, so a part of the configuration may be accepted while other parts are invalid and rejected, leading to an unwanted configuration.
As shown in Figure 4, the IP configuration can be modelled in one Variable using a structured DataType.

Figure 4 – Example of structured DataType and one Variable using the DataType
The advantages of this approach are, that the data is accessed in a transactional context and the Server can provide a consistent configuration. The structured DataType can be constructed in a way that the Server does not have to convert the data. The server can pass the data directly to the specific Client. When writing the data, this is also done in a transactional context, the Server can either accept or reject the full new configuration.
The disadvantages are that the generic Client might not be able to access and interpret the data or at least has the burden to read the DataTypeDefinition to interpret the data. The structure of the data is not visible as Nodes in the AddressSpace; additional Properties describing elements of the data structure cannot be added to the adequate places since they do not exist in the AddressSpace. Individual parts of the data cannot be read without accessing the whole data structure. This is also true for writing. The Client has to write all data of the structure, even if it only wants to change a part of it.
As shown in Figure 5, the IP configuration can be modelled combining the first two approaches, using one Variable with the structured DataType and subvariables for the individual content.

Figure 5 – Example of structured DataType and one Variable and individual Variables as subvariables
This approach combines the first two approaches and therefore also their advantages. A specific Client can access data in its native format, whereas a generic Client can access simple DataTypes of the components of the complex Variable. Additional information and references can be added to the subvariables. The data can be accessed with a transactional context or individually.
The disadvantage is that the Server must be able to provide the native format and interpret it to be able to provide the information in simple DataTypes. In general, it is more effort for the Server to provide the data individually and in a structure.
In Figure 6, it is shown how Methods can be used to provide access to the IP configuration. In this case, one Method allows accessing the combined data, and another one allows changing the IP configuration.

The advantages of this approach are that the data is accessed in a transactional context and the data is only provided on an explicit Client request. The second one is not necessarily an advantage, but when the values are calculated it may be reasonable not doing this on a subscription, but only if the Client triggers a recalculation.
The disadvantages of this approach are, that a Client cannot subscribe to changes, but only poll by calling the Method. Therefore, the example of the IP configuration using Methods is not very suitable.
Note that the Method signature could also use a structured DataType instead of the individual arguments.
The IP configuration can also be provided by the eventing mechanism of OPC UA, as shown in Figure 7. In this case, the Server can generate an Event whenever the configuration has changed. The Client can receive the changes in a transactional context, but also subscribe to only parts of the IP configuration. Changing the IP configuration from the Client is not possible with the eventing mechanism. Receiving the current configuration requires the Server to either provide the history of Events or use the condition mechanism. Therefore, the example of the IP configuration is not preferred to use eventing. A better example using events is quality data created in the Server when something is produced.
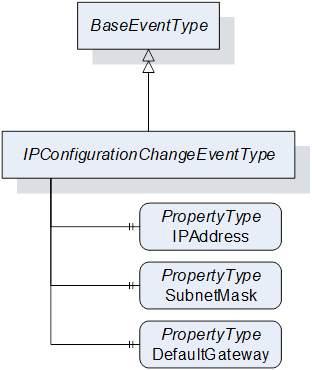
The general advantages of this approach are that the data is provided in a transactional context. Clients still can select which parts of the data they want to receive. In addition, the data can be provided exactly when it is relevant, for example, because a new part is produced, with all the needed context like job information.
The disadvantages are that this approach is read-only and only provides the data when something is happening in the server.
Note that the EventType could also be modelled using the structured DataType, potentially with individual subvariables, to provide the data in a structure.
If no transactional context is needed, it is recommended to use the first approach (see 7.5.2). If a transactional context is needed or the Client should be able to get a large amount of data instead of subscribing to individual Variables, then the third approach is recommended (see 7.5.4).
However, if the Server does not have the knowledge to interpret the structured data of the underlying system it should use the second approach (see 7.5.3). Another reason for using the second approach is, that the data is always accessed in a transaction context from an application perspective.
The approach using Methods (see 7.5.5) makes sense when additional data should be provided or the Client is triggering calculations on the Server.
The eventing mechanism (7.5.6) should be used when the creation of the data is triggered by the server, independent from a sampling rate defined by the client, or additional data like job information or the ID of the user performing some changes in the server should be provided.
The pros and cons of the first three approaches are also described in the modelling annex of OPC 10000-3.