OPC UA provides various modelling concepts (see OPC 10000-3).
- Objects structuring the AddressSpace
- Variables providing Values
- Methods that can be called by a Client and are executed by the Server
- ObjectTypes defining the semantic and structure of Objects
- VariableTypes defining the semantic and structure of Variables
- DataTypes defining the semantic and structure of Values
- Events generated by the Server that can be received by Clients
- EventTypes describing the semantic and structure of Events
- References defining relationships between Nodes
- ReferenceTypes defining the semantic of References
Based on those fundamental concepts, additional base concepts are defined like
- Conditions and Alarms as Events that are always in a state and can therefore be represented as Objects in the AddressSpace (OPC 10000-9)
- State Machines (OPC 10000-16)
- Interfaces and AddIns allowing extensibility into various ObjectType hierarchies (OPC 10000-3)
- Alias Names as searchable entry points to Nodes (OPC 10000-17)
- Dictionary References to reference external dictionaries (OPC 10000-19)
In OPC 10000-3 there is already an Annex describing how to use the modelling concepts in general, and in OPC 10000-5 there is an Annex, describing the design decisions for creating the server information (ServerType).
ObjectTypes are a very common modelling concept in OPC UA. Typically, each Companion Specification defines one or more ObjectTypes. Defining an ObjectType makes sense when it is expected that the ObjectType is used several times, either in one Server or across various Servers to provide interoperability on the model.
An ObjectType can be simple without defining any substructure, like the FolderType of the base specification. Typically, an ObjectType defines a substructure with Objects, Variables and / or Methods.
When defining an ObjectType, it needs to be considered if there is already an appropriate ObjectType it can derive from. That includes the defined semantic of the ObjectType as well as the defined substructure. The ObjectType may contain an optional substructure that is not needed but should not have any mandatory substructure that is not wanted / needed. Not only ObjectTypes of the base specification should be considered, but also ObjectTypes defined in existing Companion Specifications. The OPC Foundation provides an online search on all specifications (https://reference.opcfoundation.org/). When there is no more appropriate ObjectType defined, the BaseObjectType shall be used as base (as defined in the OPC UA Specification).
When designing a type hierarchy, the base type(s) may either be abstract or concrete.
Design decision in favour of abstract types: The main type is a template that contains all the common elements of the child types but is not “whole” itself, thus shall never be instantiated. Example: a biological parent is either a mother or a father and in the application context it makes no sense to instantiate “parent” without this information. However, both mother and father are parents.
Design decision in favour of concrete types: The super type might directly be used if no more detailed information exists. Example: To know how long a tool has been used, only the time and identifier are needed. A base type for the tool can contain only those two. For other use cases, more specific tools like drills, saws or punches may be defined, adding specific information.
Potentially, not only one ObjectType needs to be defined, but many. In this case, consider creating base ObjectTypes for common semantics and substructures.
On the other hand, it is not practical to have a very deep type hierarchy with many levels. In addition OPC UA only supports single inheritance (multiple inheritance is not supported), thus an ObjectType can be derived from only one supertype so the type hierarchy can only be organized by one aspect.
If additional aspects need to be added, composition must be used. Composition can be either done by:
- an AddIn (see OPC 10000-3), having an Object as substructure defined by an ObjectType providing a standardized BrowseName (DefaultInstanceBrowseName) and adding the aspect as defined by the AddIn-ObjectType or by
- an Interface (see OPC 10000-3), defining a substructure that is directly deployed (without grouping Object) on the ObjectType.
Composition allows definition of an aspect that can be deployed on various places in the type hierarchy, or even only on specific instances.
Therefore, subtyping should be used to refine the main characteristic of Objects of the ObjectType, and additional aspects should be defined by composition.
For example, the type hierarchy may define different types of devices (SensorType as common base type and derived a TemperatureSensorType, FlowSensorType, etc.) whereas additional aspects like the capability to lock an Object are defined by AddIns or Interfaces and added to the types.
However, even the above-mentioned example can lead to problems without multiple inheritance, as a device may support measuring temperature and flow. In this case, also the characteristic to measure a temperature and a flow should be modelled by composition (see PA-DIM for an example).
When defining a substructure of an ObjectType addressing different aspects (e.g. Identification information, measurement values, configuration parameters) everything can be referenced directly from the ObjectType, or grouping Objects can be used to address the different aspects.
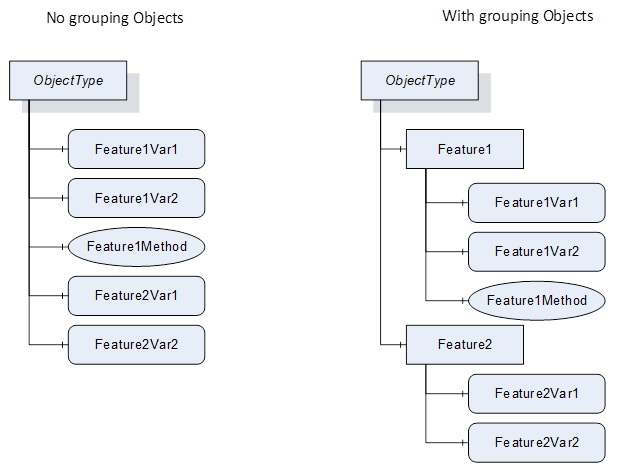
Figure 2 – Example of grouping Objects
From a pure programmatical access perspective no grouping information is required, as all individual subcomponents have their standardized names. However, from a human-readability perspective, having grouping objects increases the understandability of the provided substructure.
Grouping Objects make sense:
- if they contain several standardized subcomponents that logically belong together (like serial number, manufacturer and model for identification).
- If they contain subcomponents with no standardized BrowseNames (e.g. using the Placeholder ModellingRules, see also 7.2.8).
As a general rule of thumb, when the ObjectType has more than 30 subcomponents, having grouping Objects may be helpful. This also applies inside such a grouping Object, i.e., if the grouping Object would have more than 30 subcomponents, grouping the subcomponents with Objects as subcomponents of the grouping Object make sense. When applying the rule, potential subtypes should be considered. For example, if a base ObjectType only addresses identification but it is expected that subtypes with additional substructures are defined, it makes sense to already group the identification.
When using grouping Objects, it must be considered what ObjectType the grouping Object should have. If it groups an aspect that is expected to be used only in one place (the ObjectType the grouping Object is used), it is not necessary to create a specific ObjectType for the grouping Object, and instead it is recommended to use the FolderType. If the grouping may be used in various places, it is recommended to define an ObjectType (as AddIn), allowing to use the same grouping easily in other places.
The question whether to define an Interface or AddIn has two aspects.
- The interface is intentionally a simple and therefore limited construct (see OPC 10000-3). Therefore, depending on what needs to be defined an interface may not be an option.
- An AddIn implies a grouping Object with a standardized default name, whereas an interface can be deployed without grouping Object. Of course, even with an interface an additional grouping Object can be created and the interface gets deployed on the grouping Object.
Therefore, it is recommended to use an interface if something rather small and simple is defined (with maybe a handful of Variables and Methods) that potentially should be deployed directly on an ObjectType (without grouping Object).
In all other cases, it is recommended to define an AddIn. Potentially, an Interface can be defined and in addition an AddIn using the Interface.
As a general consideration:
- From a consumer (client) perspective, making a functionality mandatory, like a Method or Variable, is desirable because then the consumer can rely on its availability.
- From a provider (server) side making functionality mandatory can be challenging, if it cannot be provided in all cases. Therefore, as a compromise functionally is often defined as optional.
There are two ways to deal with optional functionality. One obvious way is to define the InstanceDeclaration as optional, and then the server may or may not provide the functionality.
A second option is, at least for variables, to define a specific default value implying that the information is not provided. Depending on the DataType, this might be the NULL value (if the DataType provides a NULL value (see OPC 10000-6)). Or it might be a specific value like “-1” or an empty string.
It is recommended to use the Optional ModellingRule if the provider does not support the functionality at all. If it is a Variable, where the value can also be written and thus the information can be provided by the Client, it is recommended to use the Mandatory ModellingRule and define a default behaviour, if the functionality is not available. If the Variable is not there at all, the Client does not have an option to write a value into the Variable.
Note that as an additional option, it would also be possible to have mandatory Variables and Methods, that just provide a BAD status code if not supported. It is not recommended to use this approach.
Note that optional functionality can be made mandatory by conformance units and profiles (see 3.3). In this case, the Server implementation can decide whether the conformance units or profiles are supported. Clients can discover the supported conformance units and profiles of a Server.
When an ObjectType needs to expose several subcomponents of a specific type without defining the exact number or the BrowseName, the MandatoryPlaceholder (at least one) or the OptionalPlaceholder ModellingRules are used. Often, this might be combined with a grouping Object in order to easily browse all subcomponents of that type.
When an ObjectType requires at least one subcomponent of the specific type, the grouping Object must be Mandatory and the subcomponent of the specific type must use MandatoryPlaceholder.
When the ObjectType is not required to have at least one subcomponent, options are:
- The grouping Object is Mandatory and the subcomponent uses OptionalPlaceholder
- The grouping Object is Optional and the subcomponent uses MandatoryPlaceholder
- The grouping Object is Optional and the subcomponent uses OptionalPlaceholder
When the grouping Object has additional functionality like a Method to add to its subcomponents it is recommended to make the grouping Object Mandatory and therefore the subcomponent has to use OptionalPlaceholder (Option 1).
When the grouping Object does not have any additional functionality like a Method to add to subcomponents, it is recommended to make the grouping Object optional so a client does not have to browse the empty grouping Object to figure out that it is empty. In this case, it makes sense to define the subcomponent as MandatoryPlaceholder so the grouping Object is only available when a subcomponent is included (Option 2).
However, when the model is built to be extended and a subtype may add additional functionality to the grouping Object, defining the subcomponent as OptionalPlaceholder allows subtypes to change the ModellingRule of the grouping Object without requiring a subcomponent of the specific type (Option 3).
VariableTypes are used to define the substructure, semantic and DataType of Variables. Defining VariableTypes only makes sense, if it is expected that the VariableType is used several times. Variables are typically defined in the context of an ObjectType which already defines the semantic of the Variable. Therefore, often the VariableTypes of the base specification (specifically OPC 10000-8 with VariableTypes providing ranges and engineering unit) are sufficient and no new VariableTypes need to be defined.
OPC UA distinguishes between light-weight Variables called Properties and DataVariables (see OPC 10000-3).
Properties are expected to describe the Node they belong to and have several special rules (see OPC 10000-3). They are always of VariableType PropertyType (which is not allowed to be subtyped) and referenced with a HasProperty Reference. The BrowseName defines the sematic. They are the leaf of any hierarchy, meaning they cannot be the source of any hierarchical Reference and therefore not have any Properties by themselves.
Property values typically don’t change very often, and are usually read once and not subscribed to for changes.
DataVariables are of VariableType BaseDataVariableType or any subtype and do not have the restrictions of the Properties.
The decision to use a Property or DataVariable can to a certain degree be made on a semantic level. If the value describes the Node (like the engineering unit of a Variable), it is a Property; if it is something from the real world (like a measured temperature), it is a DataVariable. However, making the decision based on the semantic is not always that clear.
There are also the functional differences between Property and DataVariable. If your Variable needs Properties (like the engineering unit), you have to use a DataVariable, even if the semantic suggests that it should be defined as a Property.
As Properties have limited functionality, the recommendation is to use Properties when it is clear from the semantic that it is just describing the characteristics of the Node and there is no need to add additional information to the Variable, also not as extensible mechanism in vendor-models or other Companion Specifications. Otherwise, it is recommended to use DataVariables.
Nodes in OPC UA have a predefined set of Attributes. They are not extensible by Companion Specifications, only the base specification may add new optional Attributes over time. If there is the need to add more description to a Node, a Property needs to be used. Common Properties are EngineeringUnits or InstrumentRange.
When considering defining a Property, check the set of Attributes defined in the base specification to determine if one of them is suitable. For example, instead of defining a Property called Description, use the corresponding Attribute. OPC UA allows all Attributes to be writable, so even if the requirement is to have a writeable description, the Attribute can be used, and no additional Property should be defined.
VariableTypes can be used to define the semantic and substructure of a Variable. A common example is the AnalogItemType providing the EngineeringUnits and InstrumentRange Properties. Sometimes, it may be helpful to define a VariableType just to describe the semantic, for example a VariableType representing SetPoints. This makes sense if the same VariableType is intended to be used in various places. The semantic of a Variable used in an ObjectType is already defined by the ObjectType and does not need to have a specific VariableType.
Typically a Method is defined on an ObjectType having the ModellingRule Optional or Mandatory. Such a Method then also appears optionally or mandatorily on the Objects of the ObjectType.
Methods defined on an ObjectType may have the ModellingRule OptionalPlaceholder or MandatoryPlaceholder. In this case, the ObjectType does not define the input and output arguments, but just the name of the Method. Instances can then use an appropriate signature. This approach should only be used when the signature cannot be standardized.
ObjectTypes may also have Methods without a ModellingRule. In this case, it is a class Method called on the ObjectType. In 8.4.1, an example is given, where such a class Method creates instances of the ObjectType.
OPC UA allows to model structured data in different ways. As a simple example, an IP-configuration may consist of an IP-Address, a Subnet-Mask, and a Default-Gateway.
This may be modelled as
- Individual Variables
- Structured DataType and one Variable using the DataType
- Structured DataType and one Variable and individual Variables as subvariables
- Methods
- Events
As shown in Figure 3, the IP configuration is modelled as individual Variables.
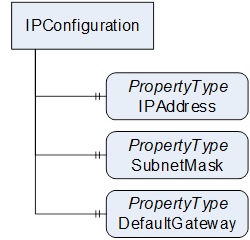
Figure 3 – Example of individual Variables
The advantages of this approach are that the complex structure of the data is visible in the AddressSpace. A generic Client can easily access the data without knowledge of user-defined DataTypes and the Client can access individual parts of the structured data. The information model may add additional information to parts of the structure (like engineering unit or precision information) or reference the individual parts of the structure from other places. Clients can write individual parts of the structure without changing other parts.
The disadvantages of this approach are that accessing the individual data does not provide any transactional context and each provides an individual timestamp. In the worst case, a Client may read part of the IP configuration before a change and other parts after a change of the configuration and therefore get an inconsistent configuration. For a specific Client the Server first has to convert the data and the Client has to convert the data, again, to get the data structure the underlying system provides. When writing the data, each part is written individually, so a part of the configuration may be accepted while other parts are invalid and rejected, leading to an unwanted configuration.
As shown in Figure 4, the IP configuration can be modelled in one Variable using a structured DataType.

Figure 4 – Example of structured DataType and one Variable using the DataType
The advantages of this approach are, that the data is accessed in a transactional context and the Server can provide a consistent configuration. The structured DataType can be constructed in a way that the Server does not have to convert the data. The server can pass the data directly to the specific Client. When writing the data, this is also done in a transactional context, the Server can either accept or reject the full new configuration.
The disadvantages are that the generic Client might not be able to access and interpret the data or at least has the burden to read the DataTypeDefinition to interpret the data. The structure of the data is not visible as Nodes in the AddressSpace; additional Properties describing elements of the data structure cannot be added to the adequate places since they do not exist in the AddressSpace. Individual parts of the data cannot be read without accessing the whole data structure. This is also true for writing. The Client has to write all data of the structure, even if it only wants to change a part of it.
As shown in Figure 5, the IP configuration can be modelled combining the first two approaches, using one Variable with the structured DataType and subvariables for the individual content.

Figure 5 – Example of structured DataType and one Variable and individual Variables as subvariables
This approach combines the first two approaches and therefore also their advantages. A specific Client can access data in its native format, whereas a generic Client can access simple DataTypes of the components of the complex Variable. Additional information and references can be added to the subvariables. The data can be accessed with a transactional context or individually.
The disadvantage is that the Server must be able to provide the native format and interpret it to be able to provide the information in simple DataTypes. In general, it is more effort for the Server to provide the data individually and in a structure.
In Figure 6, it is shown how Methods can be used to provide access to the IP configuration. In this case, one Method allows accessing the combined data, and another one allows changing the IP configuration.

The advantages of this approach are that the data is accessed in a transactional context and the data is only provided on an explicit Client request. The second one is not necessarily an advantage, but when the values are calculated it may be reasonable not doing this on a subscription, but only if the Client triggers a recalculation.
The disadvantages of this approach are, that a Client cannot subscribe to changes, but only poll by calling the Method. Therefore, the example of the IP configuration using Methods is not very suitable.
Note that the Method signature could also use a structured DataType instead of the individual arguments.
The IP configuration can also be provided by the eventing mechanism of OPC UA, as shown in Figure 7. In this case, the Server can generate an Event whenever the configuration has changed. The Client can receive the changes in a transactional context, but also subscribe to only parts of the IP configuration. Changing the IP configuration from the Client is not possible with the eventing mechanism. Receiving the current configuration requires the Server to either provide the history of Events or use the condition mechanism. Therefore, the example of the IP configuration is not preferred to use eventing. A better example using events is quality data created in the Server when something is produced.
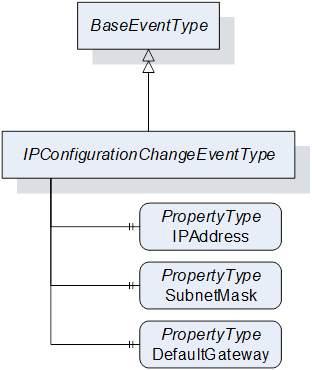
The general advantages of this approach are that the data is provided in a transactional context. Clients still can select which parts of the data they want to receive. In addition, the data can be provided exactly when it is relevant, for example, because a new part is produced, with all the needed context like job information.
The disadvantages are that this approach is read-only and only provides the data when something is happening in the server.
Note that the EventType could also be modelled using the structured DataType, potentially with individual subvariables, to provide the data in a structure.
If no transactional context is needed, it is recommended to use the first approach (see 7.5.2). If a transactional context is needed or the Client should be able to get a large amount of data instead of subscribing to individual Variables, then the third approach is recommended (see 7.5.4).
However, if the Server does not have the knowledge to interpret the structured data of the underlying system it should use the second approach (see 7.5.3). Another reason for using the second approach is, that the data is always accessed in a transaction context from an application perspective.
The approach using Methods (see 7.5.5) makes sense when additional data should be provided or the Client is triggering calculations on the Server.
The eventing mechanism (7.5.6) should be used when the creation of the data is triggered by the server, independent from a sampling rate defined by the client, or additional data like job information or the ID of the user performing some changes in the server should be provided.
The pros and cons of the first three approaches are also described in the modelling annex of OPC 10000-3.
When modelling information, there is often the need to expose a set of things. This can be a set of values, or a set of Objects. The order of those may be of importance, or not.
There are different approaches doing this in OPC UA.
- Variable with an array of potentially structured data
- Variable with an array exposing the entries as subvariables
- Referenced Objects, often grouped by a grouping Object
- Ordered Objects using the OrderedListType (see OPC 10000-5)
The simplest approach is providing a Variable with an array of values (approach 1). The array automatically has an order. Clients can subscribe to any changes in the array, and the array can be written at once. If the server supports this, even individual entries or ranges can be read from the array. The disadvantages are, that no individual entries of the array can be referenced and no additional information (e.g., engineering unit) can be added to the entries of the array.
The second approach keeps the advantages of the first, and also allows to reference individual entries of the array from other Nodes in the Information Model by referencing the subvariables. Also, it is possible to add information to the individual subvariables, like Properties. There are two ways to model this, one using the ModellingRule ExposesItsArray, and the second using the ReferenceType HasStructuredComponent. OPC 10000-3 describes the differences. The first keeps the subvariable independent of its place in the array, the second represents the order in the array, i.e., if the order changes, the values change as well. Depending whether the individual entry is of importance, or the order, one or the other approach should be used.
The third approach is to expose Objects for entries and thereby having the full capabilities of Objects, including Methods, but not providing any order. Each Object needs to be accessed individually. If the set of Objects is dynamic, the NodeVersion and ModelChangeEvent can be used to inform the Client about changes. This approach is typically combined with a grouping Object (see 7.2.8).
If the order of the Objects is of importance, the fourth approach should be used, using the OrderedObjectType. Details on the ObjectType are defined in OPC 10000-5.
The general considerations for ObjectTypes also apply for EventTypes (which are specific ObjectTypes). As EventTypes typically use Properties, a reasonable extensibility mechanism across the Type-Hierarchy of EventTypes is to define specific Interfaces to be implemented.
Events provide information at a server-defined time, so unlike Variables, which a Client either reads or which are subscribed to with a specific sample interval, an Event is generated at a specific incident (e.g. when a part has been produced) and the data can be collected so that they are consistent and exactly from the time the incident occurred, enriched with data like the job id, etc. If for a long time period nothing happens, no event is generated, and if in a short time period many events occur, all those are generated and can be received by the Client.
ReferenceTypes are used to expose the semantic of References between Nodes. The base specification already defines various ReferenceTypes (see specifically OPC 10000-5 and OPC 10000-23). If a specific semantic shall be exposed, that is not already defined, a new ReferenceType should be created. OPC UA distinguishes between hierarchical References and non-hierarchical References. For TypeDefinitions, the key aspects of the model structure are represented with hierarchical References (see OPC 10000-3).
OPC UA provides different types of DataTypes
- Abstract DataTypes which group the type hierarchy of DataTypes and can be used in VariableTypes and Variables, but not on an actual value,
- Built-in DataTypes defined in the base specification which are not extensible,
- Simple DataTypes as subtypes of Built-in DataTypes, which are transferred like the built-in DataTypes but can add additional semantic or rules,
- Enumeration DataTypes, which define the semantic of each enumeration value,
- Structured DataTypes, which define a structure based on other DataTypes,
- OptionSets, which can either be subtypes of the OptionSet DataType or subtypes of a numeric DataType
- Unions, which use structured DataTypes as base and define the allowed DataTypes
Some recommendations for DataTypes are:
- Use appropriate DataTypes, for example use the already defined DateTime instead of a Structure with Integer Values)
- Use the least complex ones doing the job (e.g., integer instead of floating point, OptionSets based on numeric values instead of based on OptionSet DataType)
- If there are several Booleans, consider combining them to an OptionSet
Structured DataTypes are the most complex DataTypes, and they do contain a few limitations that are important to understand when creating structured DataTypes. When a Server exposes information about how a DataType is used within a context (such as a Value of a Variable or a field in a Structure), it includes the information whether a subtype of the DataType is allowed to be used. This is specifically valuable when writing values. Structured DataTypes use other DataTypes to define their structure, which might include other structured DataTypes. However, there are some limitations based on how the encoding of structured DataTypes is done. If a field in a structured DataType uses a concrete structured DataType, per default it is not allowed to use a subtype of that structured DataType as it would break the encoding. The specification has added the capability to explicitly state that subtypes are allowed, and in this case the encoding is done differently (like for abstract Structure DataType, using an extension Object). If an abstract DataType other than BaseDataType or Structure should be used inside a structured DataType, the capability to use subtypes must be used. That means, if a structured DataType is defined, the capability to use subtypes has to be considered and defined accordingly.
In addition, a structured DataType may have optional fields, i.e., fields that do not have to be provided. Also, this needs to be explicitly stated. Allowing subtypes and having optional fields cannot both be combined.
Therefore, if the structured DataType requires subtypes in the fields and optional fields are also required, there are three options:
- Option 1: Use either the BaseDataType (allowing all DataTypes) or the Structure DataType (allowing all structured DataTypes) for each field that should be subtyped. Concrete DataTypes can be defined that can be used if an implementation does not need to use a subtype.
- Option 2: Define default values for all optional fields (including NULL) and use those instead of optional fields.
- Option 3: Define additional structured DataTypes used in the structured DataType, one with all optional Fields and one with all Fields allowing subtypes (or other, more semantic groupings).
All options will work but all have weaknesses. With the first option there is no type safety, because any DataType or any structured DataType can be used. The second option may lead to unclear default values (e.g., for integer values no NULL is allowed and each entry might already have a meaning). The third option provides a potentially unnecessary nesting of substructures.
Using subtypes of structured DataTypes is in several places challenging or not allowed, therefore it should be considered if the extension of a structured DataType is required. If yes, either
- all places where the DataType is used should be prepared allowing subtypes, or
- the structure already contains the extension with an array of for example key / value pairs, allowing more data in the existing structure. Depending on the usage, other information may be added as well, like engineering unit. However, the structure is always transferred as one thing, so meta data only used once should not be mixed with data transferred in a high frequency.
Note that the number of optional fields in a Structure is limited to 32 optional fields per Structure.
Recursive structures should be avoided when creating DataTypes, ObjectTypes or VariableTypes. Recursive means, that for example an ObjectType contains, either directly or indirectly, an InstanceDeclaration of itself.
However, sometimes recursive structures are helpful and cannot be avoided. In this case, the following rules should be followed:
If an ObjectType or VariableType contains an InstanceDeclaration of itself, neither Mandatory or MandatoryPlaceholder ModellingRules should be used, as this would make it either impossible to instantiate or has to lead to indirect self-references. Optional or OptionalPlaceholder ModellingRules can be used, however, implementations need to make sure that they do not end in an infinite loop when instantiating.
If a Structured DataType contains itself in a field, it needs to provide mechanisms allowing to end the recursion. In case of DataTypes a self-reference is not possible. Mechanisms allowing to end the recursion is either to define the field as optional or have an array of the DataType (potentially indirectly) that is allowed to be empty or to define mandatory fields that allow NULL values. This way, the recursion can be ended. Nevertheless, implementations need to make sure that creating a value does not end in an infinite loop and also receivers of potentially recursive values should implement a maximum level of depth they support.
Note that a structured DataType containing itself (without indirection of an array or having a field allowing subtypes) will produce issues with code generation.
Typically, instances of an OPC UA Server depend on the configuration of the Server and are based on TypeDefinitions. However, sometimes there are also standardized Instances defined by Companion Specifications.
Mostly, those are static Nodes which are entry points into the AddressSpace like the “Root” and “Objects” folders of the base specification or the “DeviceSet” of the Devices specification.
Sometimes, there are also standardized Variables (like all the capability and diagnostic information defined in OPC 10000-5). Those are not static but bound to a specific server. To work correctly in an aggregating server, it is important to mark those Nodes in the NamespaceMetadata Object of the Namespace as non-static.
It is a common requirement in Companion Specifications to define discrete values which have a string representation. A typical approach (independent of OPC UA) is to use enumeration data types, defining specific strings for internally used numeric values. The drawback on standardizing such Enumeration DataTypes in OPC UA is, that they are restricted exactly to those values. It is not allowed for a vendor to extend and even not in a new version of the specification (see 3.2.4).
There are different workarounds for this issue.
In order to allow other values, a special Enumeration “Other” can be defined. If this is selected, it is clear, that none of the regular enumerations apply. However, the drawback is that there is also no hint where to find what other value is applied. Therefore, it is not recommended to use this approach.
The MultiStateDiscreteType and MultiStateValueDisctreType work similar to an enumeration but allow different enumeration values per instance. Many Companion Specifications use this approach allowing future versions and vendors to extend the allowed enumeration values. The drawback of this approach is, that potentially (from the pure model) vendors may use completely different enumerations, not the once defined in the specification. Therefore, they need to explicitly state (by written text) in the specification, that some predefined values are to be used. This approach forces clients into looking at the instance into the enumeration values and therefore forces them into considering the extensibility and is therefore an adequate approach when extensibility is expected.
Another approach, used for example in the ConditionClass of Alarms (and with version 1.05.02 also in normal Events). The ConditionClassId Variable and also the ConditionSubClassId Variable are of DataType NodeId and point to specific ObjectTypes (either BaseConditionClassType or a subtype). This approach is actually more than an enumeration, as it allows the specialization of enumeration values in the ObjectType hierarchy. If such a specialization is required, it is recommended to use this approach.
StateMachines do provide a set of States that can be reached and therefore define kind of an enumeration with additional information like the allowed transitions and potentially causes and effects. A StateMachine itself is fix and no new States can be added, but SubStateMachines for individual States allowing to refine those. This is a more complex approach that should only be used when additional functionality of a StateMachine is needed or may be needed when refined, like defining effects or Methods that trigger the transition by a Client.
A Server managing Nodes needs to uniquely identify them in its AddressSpace. As a NodeId consists of a Namespace(Index) and an Identifier part, both parts can be used to guarantee uniqueness. Selecting the best approach depends on implementation details of the server. However, as a general guideline managing a namespace is the more expensive operation than managing another identifier in an existing namespace. Therefore, Server implementations should avoid to create many (hundreds of) namespaces and rather manage many Nodes in one namespace.
In the case of a Client creating Nodes (and thereby NodeIds) in a Server, it is recommended that the Client does not define the NodeId, but instead allows the Server to define a NodeId and return it to the Client.