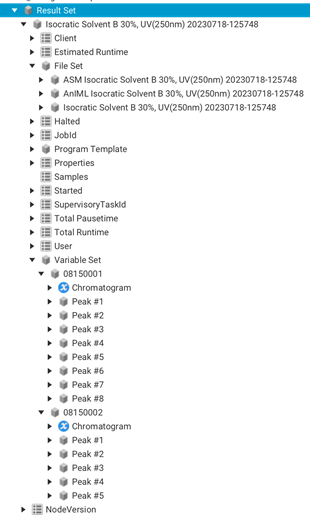
Figure 23 – VariableSet Example
Figure 23 illustrates the structure of the result data generated from a program run called "Isocratic Solvent". The result data is organized in a structured manner, comprising different sections as follows:
Various pieces of important information are presented in the upper part of the picture, including the context data that was transferred at the beginning of the program run. Context data contains details about the execution environment, settings, and other relevant parameters. Additionally, the FileSet section is visible, which contains a collection of result files generated during the program run. Moreover, runtime parameters are displayed, including the start and stop times for the program.
The VariableSet is depicted in the lower part of the picture. In this example, the VariableSet is a structured container that organizes result data on a per-sample basis. During the program run, the individual sample names were passed as parameters using the variable named "Samples". This allows for clear identification and association of the results with each specific sample. For every sample, the result data is further broken down into two main components. Firstly, the raw data of the chromatogram is provided. The raw chromatogram data is stored using the standard OPC UA data type YArrayItemType (see Figure 24).
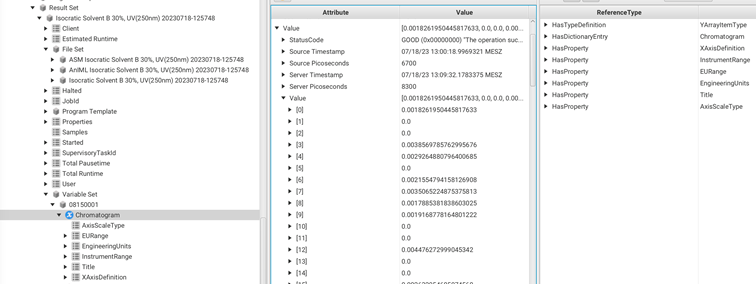
Figure 24 – Detail view of chromatogram data
This data type serves several purposes, including facilitating the representation of the X-axis definition and data scaling. Additionally, it is worth noting that the Chromatogram variable includes a reference to a dictionary entry called "Chromatogram”. This specific dictionary entry is linked to the machine-readable semantic definition of a Chromatogram in the Allotrope Ontology. The significance of this linkage lies in the fact that the data is labelled directly at its source, ensuring high-quality information for further machine-based reasoning.
In summary, this data type not only enables the representation of the Chromatagram’s raw data but also optimizes data labelling and quality, thereby supporting more effective machine-based reasoning and analysis.
Secondly, the detected peaks for each sample are displayed in Figure 25.
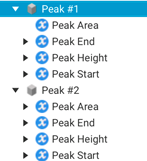
Figure 25 – Peak data of a Sample
Various computed properties, such as area and height, are represented for each peak using OPC UA variables. Importantly, each of these variables can be linked to its respective semantic definition, provided it is available. This ensures that the properties associated with each peak are well-defined and can be easily understood and interpreted.