Errata exists for this version of the document.
There are two general modes of Server Redundancy, transparent and non-transparent.
In transparent Redundancy the Failover of Server responsibilities from one Server to another is transparent to the Client. The Client is unaware that a Failover has occurred and the Client has no control over the Failover behaviour. Furthermore, the Client does not need to perform any actions to continue to send or receive data.
In non-transparent Redundancy the Failover from one Server to another and actions to continue to send or receive data are performed by the Client. The Client must be aware of the Redundant Server Set and must perform the required actions to benefit from the Server Redundancy.
The ServerRedundancy Object defined in OPC 10000-5 indicates the mode supported by the Server. The ServerRedundancyType ObjectType and its subtypes TransparentRedundancyType and NonTransparentRedundancyType defined in OPC 10000-5 specify information for the supported Redundancy mode.
OPC UA Servers that are part of a Redundant Server Set have certain AddressSpace requirements. These requirements allow a Client to consistently access information from Servers in a Redundant Server Set and to make intelligent choices related to the health and availability of Servers in the Redundant Server Set.
Servers in the Redundant Server Set shall have an identical AddressSpace including:
- identical NodeIds
- identical browse paths and structure of the AddressSpace
- identical logic for setting the ServiceLevel
The only Nodes that can differ between Servers in a Redundant Server Set are the Nodes that are in the local Server namespace like the Server diagnostic Nodes. A Client that fails over shall not be required to translate browse paths or otherwise resolve NodeIds. Servers are allowed to add and delete Nodes as long as all Servers in the Redundant Server Set will be updated with the same Node changes.
All Servers in a Redundant Server Set shall be synchronised with respect to time. This may mean installing a NTP service or a PTP service.
There are other important considerations for a redundant system regarding synchronization:
- EventIds:Each UA Server in a Transparent and HotAndMirrored Redundant Server Set shall synchronize EventIds to prevent a Client from mistakenly processing the same event multiple times simply because the EventIds are different. This is very important for Alarms & Conditions. For Cold, Warm, and Hot Redundant Server Sets Clients must be able to handle EventIds that are not synchronised. Following any Failover the Client must call ConditionRefresh defined in OPC 10000-9.
- Timestamp (Source/Server):If a Server is exposing data from a downstream device (PLC, DCS etc.) then the SourceTimestamp and ServerTimestamp reported by all redundant Servers should match as closely as possible. Clients should favour the use of the SourceTimestamp.
- ContinuationPoints:Behaviour of continuation points does not change, in that Clients must be prepared for lost continuation points. Servers in Transparent and HotAndMirrored Redundancy sets shall synchronize continuation points and they may do so in other modes.
To a Client the transparent Redundant Server Set appears as if it is just a single Server and the Client has no Failover actions to perform. All Servers in the Redundant Server Set have an identical ServerUri and an identical EndpointUrl.
Figure 26 shows a typical transparent Redundancy setup.
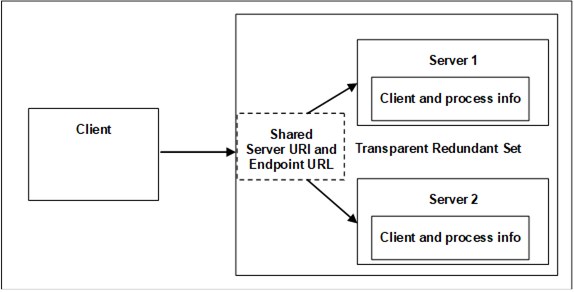
Figure 26 – Transparent Redundancy setup example
For transparent Redundancy, OPC UA provides data structures to allow Clients to identify which Servers are in the Redundant Server Set, the ServiceLevel of each Server, and which Server is currently responsible for the Client Session. This information is specified in TransparentRedundancyType ObjectType defined in OPC 10000-5. Since the ServerUri is identical for all Servers in the Redundant Server Set, the Servers are identified with a ServerId contained in the information provided in the TransparentRedundancyType Object.
In transparent Redundancy, a Client is not able to control which physical Server it actually connects to. Failover is controlled by the Redundant Server Set and a Client is also not able to actively Failover to another Server in the Redundant Server Set.
All OPC UA interactions within a given Session shall be supported by one Server and the Client is able to identify which Server that is, allowing a complete audit trail for the data. It is the responsibility of the Servers to ensure that information is synchronised between the Servers. A functional Server will take over the Session and Subscriptions from the Failed Server. Failover may require a reconnection of the Client’s SecureChannel but the EndpointUrl of the Server and the ServerUri shall not change. The Client shall be able to continue communication with the Sessions and Subscriptions created on the previously used Server.
Figure 26 provides an abstract view of a transparent Redundant Server Set. The two or more Servers in the Redundant Server Set share a virtual network address and therefore all Servers have the identical EndpointUrl. How this virtual network address is created and managed is vendor specific. There may be special hardware that mediates the network address displayed to the rest of the network. There may be custom hardware, where all components are redundant and Failover at a hardware level automatically. There may even be software based systems where all the transparency is governed completely by software.
For non-transparent Redundancy, OPC UA provides the data structures to allow the Client to identify what Servers are available in the Redundant Server Set and also Server information which tells the Client what modes of Failover the Server supports. This information allows the Client to determine what actions it may need to take in order to accomplish Failover. This information is specified in NonTransparentRedundancyType ObjectType defined in OPC 10000-5.
Figure 27 shows a typical non-transparent Redundancy setup.
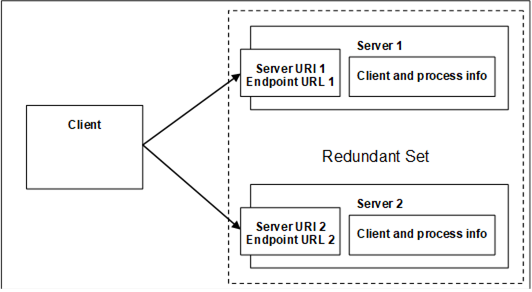
Figure 27 – Non-Transparent Redundancy setup
For non-transparent Redundancy, the Servers will have unique IP addresses. The Server also has additional Failover modes of Cold, Warm, Hot and HotAndMirrored. The Client must be aware of the Redundant Server Set and shall be required to perform some actions depending on the Failover mode. These actions are described in Table 111 and additional examples and explanations are provided in 6.6.2.4.5.2.for Cold, 6.6.2.4.5.3 for Warm, 6.6.2.4.5.4 for Hot and 6.6.2.4.5.5 for HotAndMirrored.
A Client needs to be able to expect that the SourceTimestamp associated with a value is approximately the same from all Servers in the Redundant Server Set for the same value.
The ServiceLevel provides information to a Client regarding the health of a Server and its ability to provide data. See OPC 10000-5 for a formal definition for ServiceLevel. The ServiceLevel is a byte with a range of 0 to 255, where the values fall into the sub-ranges defined in Table 109.
The algorithm used by a Server to determine its ServiceLevel within each sub-range is Server specific. However, all Servers in a Redundant Server Set shall use the same algorithm to determine the ServiceLevel. All Servers, regardless of Redundant Server Set membership, shall adhere to the sub-ranges defined in Table 109.
Table 109 – ServiceLevel Ranges
|
Sub-range |
Name |
Description |
|
0-0 |
Maintenance |
The Failed Server is in maintenance sub-range. Therefore, new Clients shall not connect and currently connected Clients shall disconnect. The Server should expose a target time at which the Clients are able to reconnect. See EstimatedReturnTime defined in OPC 10000-5 for additional information. A Server that has been set to Maintenance is typically undergoing some maintenance or updates. The main goal for the Maintenance ServiceLevel is to ensure that Clients do not generate load on the Server and allow time for the Server to complete any actions that are required. This load includes even simple connections attempts or monitoring of the ServiceLevel. The EstimatedReturnTime indicates when the Client should check to see if the Server is available. If updates or patches are taking longer than expected the Client may discover that the EstimatedReturnTime has been extended further into the future. If the Server does not provide the EstimatedReturnTime, or if the time has lapsed, the Client should use a much longer interval between reconnects to a Server in the Maintenance sub-range than its normal reconnect interval. |
|
1-1 |
NoData |
The Failed Server is not operational. Therefore, a Client is not able to exchange any information with it. The Server most likely has no data other than ServiceLevel, ServerStatus and diagnostic information available. A Failed Server in this sub-range has no data available. Clients may connect to it to obtain ServiceLevel, ServerStatus and other diagnostic information. If the underlying system has failed, typically the ServerStatus would indicate COMMUNICATION_FAULT_6. The Client may monitor this Server for a ServerStatus and ServiceLevel change, which would indicate that normal communication could be resumed. |
|
2-199 |
Degraded |
The Server is partially operational, but is experiencing problems such that portions of the AddressSpace are out of service or unavailable. To understand Client options, see Degraded Servers discussion in this section. An example usage of this ServiceLevel sub-range would be if 3 of 10 devices connected to a Server are unavailable. Servers that report a ServiceLevel in the Degraded sub-range are partially able to service Client requests. The degradation could be caused by loss of connection to underlying systems. Alternatively, it could be that the Server is overloaded to the point that it is unable to reliably deliver data to Clients in a timely manner. If Clients are experiencing difficulties obtaining required data, they shall switch to another Server if any Servers in the Healthy range are available. If no Servers are available in the Healthy range, then Clients may switch to a Server with a higher ServiceLevel or one that provides the required data. Some Clients may also be configured for higher priority data and may check all Degraded Servers, to see if any of the Servers are able to report as good quality the high priority data, but this functionality would be Client specific. In some cases a Client may connect to multiple Degraded Servers to maximize the available information. |
|
200-255 |
Healthy |
The Server is fully operational. Therefore, a Client can obtain all information from this Server. The sub-range allows a Server to provide information that can be used by Clients to load balance. An example usage of this ServiceLevel sub-range would be to reflect the Server’s CPU load where data is delivered as expected. Servers in the Healthy ServiceLevel sub-range are able to deliver information in a timely manner. This ServiceLevel may change for internal Server reason or it may be used for load balancing described in 6.6.2.4.3. Client shall connect to the Server with the highest ServiceLevel. Once connected, the ServiceLevel may change, but a Client shall not Failover to a different Server as long as the ServiceLevel of the Server is accessible and in the Healthy sub-range. |
In systems where multiple Hot Servers (see 6.6.2.4.5.4) are available, the Servers in the Redundant Server Set can share the load generated by Clients by setting the ServiceLevel in the Healthy sub-range based on the current load. Clients are expected to connect to the Server with the highest ServiceLevel. Clients shall not Failover to a different Server in the Redundant Server Set of Servers as long as the Server is in the Healthy sub-range. This is the normal behaviour for all Clients, when communicating with redundant Servers. Servers can adjust their ServiceLevel based on the number of Clients that are connected, CPU loading, memory utilization, or any other Server specific criteria.
For example in a system with 3 Servers, all Servers are initially at ServiceLevel 255, but when a Client connects, the Server with the Client connection sets its level to 254. The next Client would connect to a different Server since both of the other Servers are still at 255.
It is up to the Server vendor to define the logic for spreading the load and the number of expected Clients, CPU load or other criteria on each Server before the ServiceLevel is decremented. It is envisioned that some Servers would be able to accomplish this without any communication between the Servers.
The Failover mode of a Server is provided in the ServerRedundancy Object defined in OPC 10000-5. The different Failover modes for non-transparent Redundancy are described in Table 110.
Table 110 – Server Failover Modes
|
Name |
Description |
|
Cold |
Cold Failover mode is where only one Server can be active at a time. This may mean that redundant Servers are unavailable (not powered up) or are available but not running (PC is running, but application is not started) |
|
Warm |
Warm Failover mode is where the backup Server(s) can be active, but cannot connect to actual data points (typically, a system where the underlying devices are limited to a single connection). Underlying devices, such as PLCs, may have limited resources that permit a single Server connection. Therefore, only a single Server will be able to consume data. The ServiceLevel Variable defined in OPC 10000-5 indicates the ability of the Server to provide its data to the Client. |
|
Hot |
Hot Failover mode is where all Servers are powered-on, and are up and running. In scenarios where Servers acquire data from a downstream device, such as a PLC, then one or more Servers are actively connected to the downstream device(s) in parallel. These Servers have minimal knowledge of the other Servers in their group and are independently functioning. When a Server fails or encounters a serious problem then its ServiceLevel drops. On recovery, the Server returns to the Redundant Server Set with an appropriate ServiceLevel to indicate that it is available. |
|
HotAndMirrored |
HotAndMirrored Failover mode is where Failovers are for Servers that are mirroring their internal states to all Servers in the Redundant Server Set and more than one Server can be active and fully operational. Mirroring state minimally includes Sessions, Subscriptions, registered Nodes, ContinuationPoints, sequence numbers, and sent Notifications. The ServiceLevel Variable defined in OPC 10000-5 should be used by the Client to find the Servers with the highest ServiceLevel to achieve load balancing. |
Each Server maintains a list of ServerUris for all redundant Servers in the Redundant Server Set. The list is provided together with the Failover mode in the ServerRedundancy Object defined in OPC 10000-5. To enable Clients to connect to all Servers in the list, each Server in the list shall provide the ApplicationDescription for all Servers in the Redundant Server Set through the FindServers Service. This information is needed by the Client to translate the ServerUri into information needed to connect to the other Servers in the Redundant Server Set. Therefore a Client needs to connect to only one of the redundant Servers to find the other Servers based on the provided information. A Client should persist information about other Servers in the Redundant Server Set.
Table 111 defines a list of Client actions for initial connections and Failovers.
Table 111 – Redundancy Failover actions
|
Failover mode and Client options |
Cold |
Warm |
Hot (a) |
Hot (b) |
HotAndMirrored |
|
On initial connection in addition to actions on Active Server: |
|
|
|
|
|
|
Connect to more than one OPC UA Server. |
|
X |
X |
X |
Optional for status check |
|
Create Subscriptions and add monitored items. |
|
X |
X |
X |
|
|
Activate sampling on the Subscriptions. |
|
|
X |
X |
|
|
Activate publishing. |
|
|
|
X |
|
|
At Failover: |
|
|
|
|
|
|
OpenSecureChannel to backup OPC UA Server |
X |
|
|
|
X |
|
CreateSession on backup OPC UA Server |
X |
|
|
|
|
|
ActivateSession on backup OPC UA Server |
X |
|
|
|
X |
|
Create Subscriptions and add monitored items. |
X |
|
|
|
|
|
Activate sampling on the Subscriptions. |
X |
X |
|
|
|
|
Activate publishing. |
X |
X |
X |
|
|
Clients communicating with a non-transparent Redundant Server Set of Servers require some additional logic to be able to handle Server failures and to Failover to another Server in the Redundant Server Set. Figure 28 provides an overview of the steps a Client typically performs when it is first connecting to a Redundant Server Set. The figure does not cover all possible error scenarios.
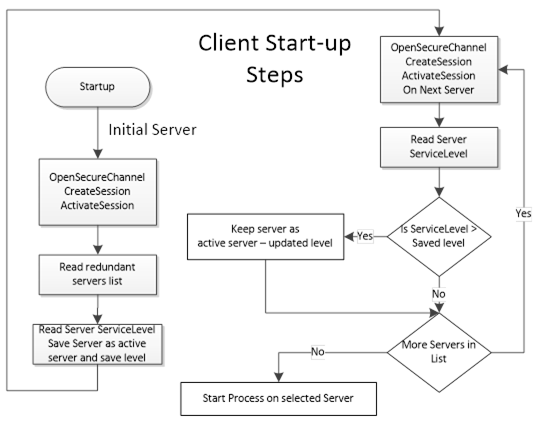
Figure 28 – Client Start-up Steps
The initial Server may be obtained via standard discovery or from a persisted list of Servers in the Redundant Server Set. But in any case the Client needs to check which Server in the Server set it should connect to. Individual actions will depend on the Server Failover mode the Server provides and the Failover mode the Client will make use.
Clients once connected to a redundant Server have to be aware of the modes of Failover supported by a Server since this support affects the available options related to Client behaviour. A Client may always treat a Server using a lesser Failover mode, i.e. for a Server that provides Hot Redundancy, a Client might connect and choose to treat it as if the Server was running in Warm Redundancy or Cold Redundancy. This choice is up to the client. In the case of Failover mode HotAndMirrored, the Client shall not use Failover mode Hot or Warm as it would generate unnecessary load on the Servers.
A Cold Failover mode is where the Client can only connect to one Server at a time. When the Client loses connectivity with the Active Server it will attempt a connection to the redundant Server(s) which may or may not be available. In this situation the Client may need to wait for the redundant Server to become available and then create Subscriptions and MonitoredItems and activate publishing. The Client shall cache any information that is required related to the list of available Servers in the Redundant Server Set. Figure 29 illustrate the action a Client would take if it is talking to a Server using Cold Failover mode.
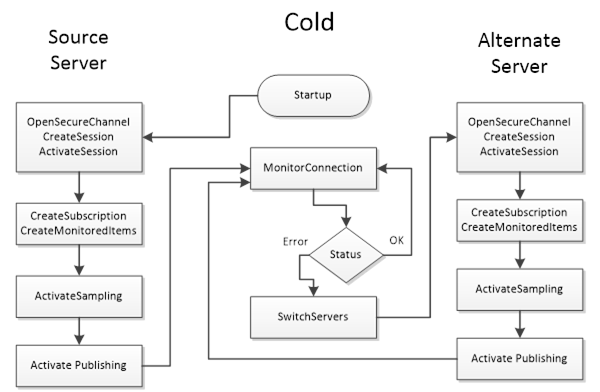
Note: There may be a loss of data from the time the connection to the Active Server is interrupted until the time the Client gets Publish Responses from the backup Server.
A Warm Failover mode is where the Client should connect to one or more Servers in the Redundant Server Set primarily to monitor the ServiceLevel. A Client can connect and create Subscriptions and MonitoredItems on more than one Server, but sampling and publishing can only be active on one Server. However, the active Server will return actual data, whereas the other Servers in the Redundant Server Set will return an appropriate error for the MonitoredItems in the Publish response such as Bad_NoCommunication. The one Active Server can be found by reading the ServiceLevel Variable from all Servers. The Server with the highest ServiceLevel is the Active Server. For Failover the Client activates sampling and publishing on the Server with the highest ServiceLevel. Figure 30 illustrates the steps a Client would perform when communicating with a Server using Warm Failover mode.
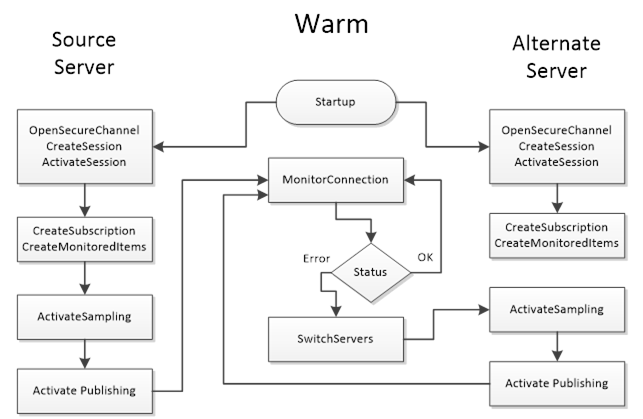
Note: There may be a temporary loss of data from the time the connection to the Active Server is interrupted until the time the Client gets Publish Responses from the backup Server.
A Hot Failover mode is where the Client should connect to two or more Servers in the Redundant Server Set and to subscribe to the ServiceLevel variable defined in OPC 10000-5 to find the highest ServiceLevel to achieve load balancing; this means that Clients should issue Service requests such as Browse, Read, Write to the Server with the highest ServiceLevel. Subscription related activities will need to be invoked for each connected Server. Clients have the following choices for implementing subscription behaviour in a Hot Failover mode:
- Client connects to multiple Servers and establishes subscription(s) in each where only one is Reporting; the others are Sampling only. The Client should setup the queue size for the MonitoredItems such that it can buffer all changes during the Failover time. The Failover time is the time between the connection interruption and the time the Client gets Publish Responses from the backup Server. On a fail-over the Client must enable Reporting on the Server with the next highest availability.
- Client connects to multiple Servers and establishes subscription(s) in each where all subscriptions are Reporting. The Client is responsible for handling/processing multiple subscription streams concurrently.
Figure 31 illustrate the functionality a Client would perform when communicating with a Server using Hot Failover mode (the figure include both (a) and (b) options)
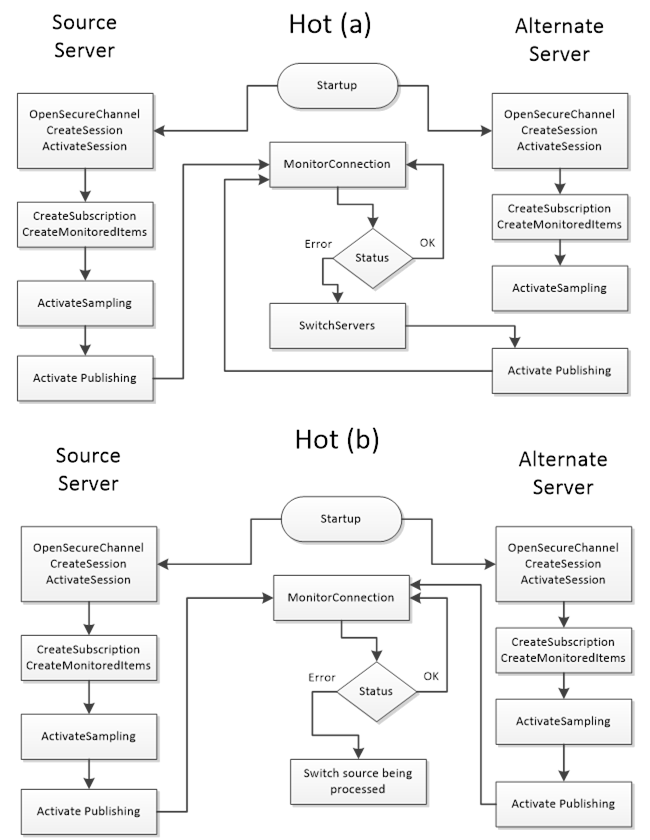
Clients are not expected to automatically switch over to a Server that has recovered from a failure, but the Client should establish a connection to it.
A HotAndMirrored Failover mode is where a Client only connects to one Server in the Redundant Server Set because the Server will share this session/state information with the other Servers. In order to validate the capability to connect to other redundant Servers it is allowed to create Sessions with other Servers and maintain the open connections by periodically reading the ServiceLevel. A Client shall not create Subscriptions on the backup Servers for status monitoring (to prevent excessive load on the Servers). This mode allows Clients to fail over without creating a new context for communication. On a fail-over the Client will simply create a new SecureChannel on an alternate Server and then call ActivateSession; all Client activities (browsing, subscriptions, history reads, etc.) will then resume. Figure 32 illustrate the behaviour a Client would perform when communicating to a Server in HotAndMirrored Failover mode.
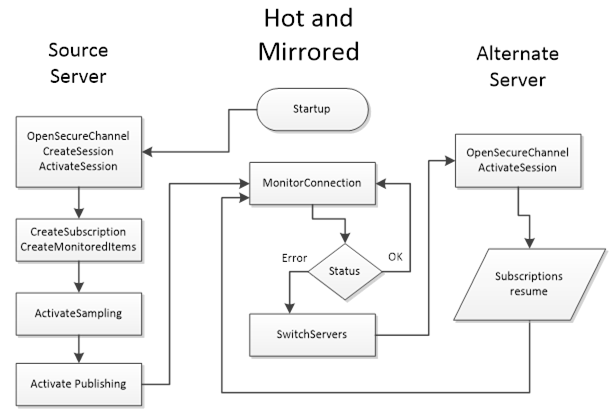
Figure 32 – HotAndMirrored Failover
This Failover mode is similar to the transparent Redundancy. The advantage is that the Client has full control over selecting the Server. The disadvantage is that the Client needs to be able to handle Failovers.
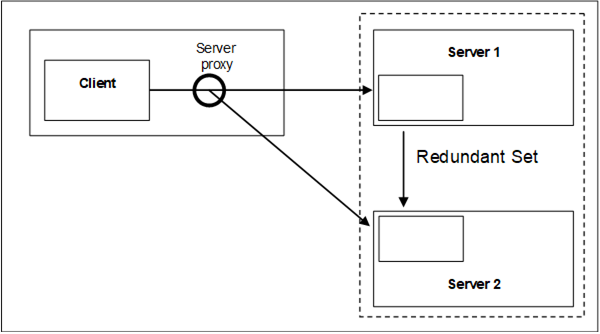
A vendor can use the non-transparent Redundancy features to create a Server proxy running on the Client machine to provide transparent Redundancy to the client. This reduces the amount of functionality that needs to be designed into the Client and to enable simpler Clients to take advantage of non-transparent Redundancy. The Server proxy simply duplicates Subscriptions and modifications to Subscriptions, by passing the calls on to both Servers, but only enabling publishing and sampling on one Server. When the proxy detects a failure, it enables publishing and/or sampling on the backup Server, just as the Client would if it were a Redundancy aware Client.
Figure 33 shows the Server proxy used to provide transparent Redundancy.